Czym Jest Inżynieria Danych (Data Engineering)

Zacząć od definicji inżynierii danych (data engineering), copy-paste z Wikipedii, czy może opowiedzieć moją historię i to jak, czysto subiektywnie – postrzegam ten temat?

Będzie historia, ale zanim cofniemy się parę lat wstecz, powiem Ci co wyniesiesz z tego artykułu:
- dowiesz się, czym jest inżynieria danych
- jaka może być jedna z dróg prowadząca do roli Data Engineer
- poznasz dziedziny (grupy) inżynierii danych w których można się specjalizować
- pokażę Ci co jest w tym momencie (2020) „hot” w świecie danych
- jak nie pogubić się w gąszczu sloganów, technologii i skrótów
Wcześniej na blogu pojawił się wpis, Jak zacząć przygodę z danymi w nim również pisałem o inżynierii danych. Spokojnie, ten post nie będzie kalką. Z tamtego artykułu dowiesz się o ogólnych koncepcjach, przydatnych materiałach i osobach, które warto śledzić. Ten wpis tworzę z myślą pełnoprawnego wprowadzenia w temat inżynierii danych.
Moja Historia
Dobrze, skoro przydługi wstęp mamy już za sobą, to teraz cofnijmy się 10 lat wstecz, mamy rok 2010, termin Data Engineer, raczkował, żeby nie powiedzieć, że zwyczajnie nie istniał.
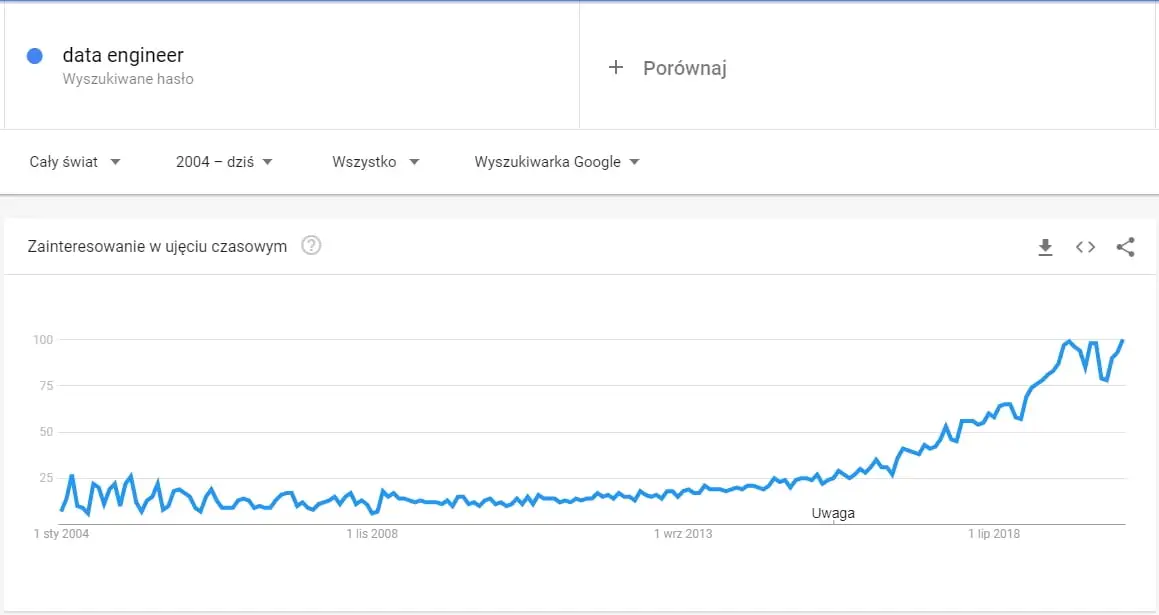 Trend, dla frazy data engineer od roku 2004, na podstawie danych z Google Trends.
Trend, dla frazy data engineer od roku 2004, na podstawie danych z Google Trends.
10 lat minęło …
Przedstawiam Ci … mnie 10 lat młodszego, studiującego Informatykę na Krakowskiej Politechnice, raczej nie do końca świadomego jeszcze czym chcę się zająć po studiach, no ale na pewno będzie to „informatyka”. Pieniążki w tamtym okresie się nie przelewały, banknot z Panem Jagiełło ciężko było znaleźć w portfelu, więc szukamy pracy.
Trzymając się mocno ukutej frazy „głupi ma zawsze szczęście” (lub jak wolisz „szczęście sprzyja lepszym”) przez jeden z portali ogłoszeniowych trafiłem na ofertę „w zawodzie”, tj. na ofertę związaną z działką IT, mianowicie – Programista Baz Danych.
No perełka pomyślałem sobie, bazy znam, w końcu mieliśmy mocny jeden semestr nauki o krotkach, encjach i relacjach. SELECT * nie ma przede mną tajemnic idę (jak dzik w szyszki) tj. aplikuję z nadzieją pozytywnego rozpatrzenia mojej prośby. Los i mój nowy pracodawca (który nomen omen okazał się świetnym człowiekiem i utrzymujemy przyjacielski kontakt do dzisiaj) chciał dać mi szansę, a ja nie chciałem tej szansy zmarnować. I tak w trybie przyspieszonym w ciągu pierwszych 2 dni pracy przypomniałem sobie cały semestr baz danych, i dalej pracując zgłębiałem świat danych (wtedy pracując z bazą Firebird).
STOP: jak to jest związane z inzynierą danych? Do tego dojdziemy, najpierw pozwól, że powiem Ci jakie technologie i umiejętności mi towarzyszyły w tej pracy:
- Bazy danych (relacyjne) – Firebird
- SQL
- XML
- PHP (w małym stopniu)
- Analiza problemu i wymagań
- Praca bezpośrednio z klientem zewnętrznym
- Wsparcie i szkolenie po procesie wdrożenia
Jak zobaczysz dalej w tekście, większość z punktów wyżej, pomoże mi w kolejnych etapach mojej kariery i będzie mocno związana ze ścieżką inżyniera danych.
Konsultantem być
Fast forward 2 lata mamy rok 2012, nowa praca, tym razem wchodzę w świat Business Intelligence. I teraz będąc całkowicie z Tobą szczerym, gdy zaczynałem nie miałem kompletnie pojęcia (oprócz definicji z Google ;)) czym BI jest.
Wiedziałem, że są bazy danych, SQL, przetwarzanie danych, raporty. Generalnie w świecie baz danych i SQL czułem się jak ryba w wodzie, a że „wyzwań się nie boję” (ja mężczyzna pracujący jestem), stwierdziłem, że jeżeli znowu szczęście trochę pomoże to ja ze swojej strony, zrobię wszystko żeby nadrobić ewentualne braki w wiedzy i pomóc nowemu pracodawcy.
Fortunnie tak się właśnie stało, dostałem szansę pracować jako Konsultant Business Intelligence przy projekcie hurtowni danych w technologiach Microsoft a dalej budować od zera hurtownię w oparciu o bazę danych Oracle i narzędzie do procesów ETL również tej firmy – Oracle Warehouse Builder.
Dobrze, zatrzymajmy się na moment padło parę buzzwordów, podsumujmy to troszeczkę (definicję, są moje autorskie, mogą się różnić od książkowych):
- Business Intelligence – procesy, narzędzia i metody wspomagania decyzji biznesowych w przedsiębiorstwie.
- Hurtownia Danych – jest to swego rodzaju baza danych, która jest zorganizowana pod kątem agregowania i przechowywania danych przedsiębiorstwa lub jakiejś dziedziny biznesowej przedsiębiorstwa.
- Stos Technologiczny Microsoft – technologie Microsoft związane ze światem danych i Business Intelligence (w tamtym momencie był to: baza danych SQL Server, SSIS (SQL Server Integration Services) pomagające w procesach przetwarzania danych, SSAS (SQL Server Analysis Services) do budowania procesów analitycznych i tzw. kostek OLAP
- Oracle – dostawca jednej z najbardziej popularnych relacyjnych baz danych
- ETL – proces przetwarzania danych cechujących się, pobraniem danych ze źródła (Extract), transformacji danych zgodnie z potrzebami biznesowymi (transform) i załadowaniem danych do hurtownii (innej bazy danych) (Load)
- Oracle Warehouse Builder – narzędzie do wizualnego tworzenia procesów ETL
Praca w nowej firmie pokazała mi, że można pracować z danymi i wiedzieć niewiele o pracy z danymi. Zabrzmiało enigmatycznie, ale generalnie chodzi o to, że abstrahując nawet od świata inżynierii danych, informatyka (a pewnie inne kierunki też) jest tak szerokim tematem, że znając jeden element, można kompletnie nie znać innego, który wydawałoby się jest przecież tożsamy (służy do rozwiązania tych samych problemów). I tak np. znając bazy danych w oparciu o bazę Firebird, można ich kompletnie nie znać patrząc z perspektywy SQL Servera czy Oracle. Pewne fundamenty i koncepcję są tożsame i tutaj akurat nie ma dyskusji, natomiast faktyczne rozwiązania technologiczne mogą w sporym stopniu różnić się między sobą.
STOP: czy to już jest inżynieria danych? Powolutku nie uprzedzajmy faktów. Co warto zapamiętać z tej części to:
- technologie mogą się zmieniać, fudamentalne koncpecje i metody są stałe
- można być specjalistą w rzeczy A, lub wiedzieć trochę o rzeczach od A do Z
- nazwy stanowisk mogą być różne, ale funkcje i zadania na tych stanowiskach podobne
Mamo, Tato, jestem inżynierem
Przewijamy do przodu o kolejne 1,5 roku, po tym czasie zostaję inżynierem oprogramowania (Software Engineer), ooo już przynajmniej jeden człon się zgadza z tytułem tego postu.

Jako, że w poprzedniej pracy na bazie danych Oracle zjadłem zęby (a przynajmniej tak chciałem wierzyć), stwierdziłem, że to jest kierunek w którym chcę się rozwijać a dodatkowo łączyć to ze światem biznesowym – hurtownie danych, procesy biznesowe, analityka i wizualizacje. Podobnie jak wcześniej, tak i tym razem, okazało się, że jest taka szansa i mogłem wziąć udział w projekcie dla jednego z banków inwestycyjnych.
W codziennej pracy, tworzyłem procesy przetwarzania i transformacji danych, które dalej pozwalały na wykorzystanie danych w systemach analitycznych i tworzenie warstwy wizualizacji. Wizualizacje i analityka z kolei, miały pomóc w podejmowaniu trafnych decyzji biznesowych. Kolejny raz dowiedziałem się, jak mało wiem, i jak nieoceniona jest praca ze specjalistami w swojej dziedzinie. W tym okresie, mogłem się uczyć i pracować z jednymi z lepszych (przynajmniej według mnie i mojej wiedzy) ekspertami od Oracle. Poznałem jak wygląda dobre zarządzanie zespołem i projektem. Dodatkowo dowiedziałem się, że testy danych i logiki przetwarzania to nie mityczny jednorożec i faktycznie istnieją, mało tego dobrze zrobione dają faktycznie sporo wartości.
STOP: Podsumujmy szybciutko, jeszcze nie data engineering ale już tak prawie, może trochę nieśmiało, z czym mogłem się mierzyć:
- baza danych Oracle
- wyzwania wydajnościowe
- przetwarzanie dużej (nie ogromnej) ilości danych
- procesy przetwarzania danych budowane bez potrzeby narzędzi graficznych (skrypty + procedury bazodanowe)
- testy jako element dobrze funkcjonującej hurtowni danych
BI, miłość na całe życie
Zbliżamy się do czasów obecnych, jeszcze tylko 5 lat dzieli nas od chwili kiedy piszę dla Ciebie te słowa. Uwaga pojawia się rola data engineer wreszcie 🙂
Spłycając historię, stwierdziłem, że w zasadzie, to fajnie by było tak na poważnie wrócić do świata Business Intelligence, stojąc tak poniekąd pomiędzy twardym przetwarzaniem danych (hurotwnią itd.) a ścisłą współpracą z biznesem wdrażaniem logiki biznesowej i budowaniu przydatnych wizualizacji.
Walcząc tym razem jako Programista Business Intelligence, miałem przyjemność tworzyć warstwę hurtownii danych, jak również warstwę analityki i wizualizacji korzystając z jednego narzędzia (platformy), której twórcą była firma Qlik. Sprawiało to całkiem sporo frajdy i dość ciekawych problemów, bo przecież można by zbudować osobno hurtownię danych w oparciu o dostępne produkty i osobno analityke / wizualizację, ale czy trzeba?
No i dokładnie w tym okresie weszła ona, cała na biało … nowo-mowa, albo nowa-moda wprost z USA, pachniała nowością.
O czym mowa o uwspólnianiu nazw stanowisk w świecie korporacji. I tak z przyzwoitego, Programisty Business Intelligence stałem się Inżynierem Danych (Data Engineer).
Czy spłynęła na mnie wiedza wszystkich pokoleń inżynierów danych? Czy moje umiejętności przetwarzania danych skoczyły 10 krotnie … no nie. Niezmiennie moim zadaniem było, przetworzenie danych z systemu źródłowego, do hurtownii danych (lub innego miejsca, które taką rolę będzie pełnić), zaaplikowanie logiki biznesowej, przygotowanie warstwy analitycznej i stworzenie raportów lub całych aplikacji pozwalających odpowiednim działom przedsiębiorstwa na łatwiejszą pracę i dostanie „od ręki” potrzebnych informacji.
Pan od danych
No i w końcu dzisiaj (tj. w lipcu 2020) mam przyjemność pisać dla Ciebie ten artykuł, jako Pan od danych, bez tytułów i nagłówków, Staram się popularyzować naukę o danych, ich przetwarzaniu, analizie i wizualizacji, tak żeby dane nie miały przed Tobą tajemnic a ich świadome wykorzystanie pomogło Ci odnieść sukces – jakkolwiek go sobie nie wyobrażasz.
No to pięknie, kilkanaście akapitów dalej a tutaj ciągle brakuje definicji inżynierii danych i opisu roli inżyniera danych.
Czym więc jest ta magiczna inżynieria danych, czy jest to tylko tytuł nadawany przez jaśnie panującego dyrektora działu HR, a jutro będzie się nazywał zgoła inaczej? Odpuśćmy sobie żarty, skupmy się na cechach roli.
Co wchodzi w skład inżynierii danych?
Tak, żeby zacząć z mocnej strony zerknij na poniższą grafikę technologii w świecie Big Data i szeroko rozumianego AI.

Źródło: Matt Turck – Big Data and AI Landscape for 2018
Szok troszeczkę co? No dobra a teraz powolutku. Poniższe punkty nie wyczerpują tematu, i zależało mi bardziej na tym, żeby pokazać Ci kierunek z którym inżynieria danych się wiąże.
Sposoby przechowywania danych
- bazy danych
- nośniki w chmurze publicznej np. S3
- cold / hot storage
- in-memory
Ultra istotna kwestia, w końcu gdzieś dane należy przechowywać, żeby móc je przetwarzać. Przechowywanie danych jest o tyle istotną kwestią, że z biegiem lat, podejścia ewoluują, danych przybywa w astronomicznym tempie i coś co kiedyś było de facto standardem – patrz relacyjne bazy danych – w dzisiejszym świecie może nie być wystarczające. Warto patrzeć na swoje projekty przetwarzania danych pod kątem tego, jak wykorzystujemy nasze dane, czy 100% danych jest przetwarzanych i potrzebnych, czy może mam X% danych historycznych, których nie przetwarzamy lub wystarczyłoby je zagregować do wyższego poziomu a dane szczegółowe zarchiwizować. Czy chcemy wykorzystać pamięć i pompować nasze dane do rozwiązań in-memory w celu zwiększenia wydajności. Te i wiele innych podobnych pytań warto sobie postawić w kontekście sposobów przechowywania danych.
Pobieranie danych z systemów źródłowych
- znajomość systemów źrodłowych
- bazy danych relacyjne
- bazy danych nierelacyjne
Kolejny ważny punkt, skąd bierzemy dane. To nie manna z nieba, która w automagiczny sposób wpada do naszych systemów. W znacznej większości przypadków, pobieramy dane z systemów źródłowych naszego przedsiębiorstwa lub firm trzecich w celu ich przechowywania i dalszego przetwarzania. Tych systemów może być wiele, i nierzadko różnią się istotnie pomiędzy sobą strukturą i formą w jakiej wystawiają dane do dalszego procesowania. Od systemu o relacyjnych strukturach, gdzie znajomość schematu i tego jak wykorzystywane są relacje i atrybuty w systemie jest istotna. Po źródła nierelacyjnej, gdzie istotna może być informacja o ilości danych które powstają w danej jednostce czasu, oraz o tym czy cały ich zakres powinien brać udział w dalszym przetwarzaniu.
Metody przetwarzania danych
- procesy ETL / ELT
- procesowanie „batchowe”
- procesowanie strumieniowe
- praca z metadanymi
- dbanie o jakość danych
Metody przetwarzania danych to serce systemu. Oprócz samych sposobów przetwarzania danych takich jak procesy ETL (Extract – Transform – Load) czy ELT (Extract – Load – Transform) i rodzajów ich przetwarzania – przetwarzanie w partiach lub przetwarzaniu strumieniowym równie istotną (jeżeli nie najważniejszą) kwestią jest jakość danych i metadane. To często te dwie ostatnie kwestie determinują to czy użytkownicy końcowi będą nam ufać czy raczej „boksować się” kwestionując to co im dostarczamy.
Architektura systemów przetwarzania danych
- tradycjna hurtownia danych w oparciu o system batchowy
- data lake
- połączenie systemu batchowego i strumieniowania danych (systemy Big Data)
Tak jak wspomniałem wyżej przy przechowywaniu danych, ilość danych rośnie w zawrotnym tempie i nie wydaje się by ten trend się odwrócił w przyszłości (wręcz przeciwnie). Architektury systemów przetwarzania danych, które jeszcze niedawno, były wzorcem i odpowiadały na wszystkie potrzeby biznesowe (patrz tradycyjne hurtownie danych i przetwarzanie partiami) dzisiaj często przestają być wystarczające. Wraz z przyrostem danych i chęcią posiada wiedzy biznesowej w czasie prawie rzeczywistym, architektura systemów musiała ulec zmianie.
Infrastuktura wspierająca inżynierię danych
- chmura publiczna
- serwery lokalne (on-premise)
- rozwiązania hybrydowe
- wirtualizacji / konteneryzacja
Trzymanie komputera stacjonarnego pod biurkiem jako serwera przechowującego dane przedsiębiorstwa nie przejdzie 🙂 Chmura publiczna staje się nowym standardem, i coraz więcej firm decyduje się na przejście z rozwiązań tzw. on-premise (zarządzanych i trzymanych wewnątrz przedsiębiorstwa) na przejście do chmury. Jak ze wszystkim tak i tutaj możemy spotkać się z wadami i zaletami takiego rozwiązania. Dlatego przed hurra optymistycznym wkroczeniem do chmury warto się zastanowić nad decyzją, policzyć koszty, sprawdzić czy wszystkie systemy przedsiębiorstwa zostaną przeniesione czy część. Jeżeli część to czy ta część będzie miała wpływ na wydajność np. systemy źródłowe w chmurze a analityka na lokalnych serwerach przedsiębiorstwa? Czy mamy kompetencje aby wejść do świata chmury czy musimy je stworzyć (lub zaprosić do pomocy zewnętrzne firmy). To nie są łatwe i proste decyzje, dlatego karta, ołówek, plusy, minusy i dopiero decyzja.
Tutaj garść statystyk o użyciu rozwiazań „chmurowych”: https://hostingtribunal.com/blog/cloud-computing-statistics/#gre
Analityka i wizualizacja
Skoro pobraliśmy i przetworzyliśmy dane, to wypadałoby teraz je w zgrabnej formie zaprezentować, tak żeby można było podjąć rzeczywistą akcję biznesową na ich podstawie w końcu takich jest nasz cel 🙂 W tym punkcie jak i w pozostałych kwestią do rozważenia jest fakt czy warstwę wizualizacji / analityki chcemy tworzyć sami w oparciu o nasze autorskie rozwiązanie czy może skorzystamy z rozwiązań dostępnych na rynku co znowu sprowadza się do rozważań, które dostawca, cena, ograniczenia itp.
Ok ok, trochę chyba za dużo tych tematów. Czyli chcesz mi powiedzieć, że ja to wszystko muszę umieć, żeby być inżynierem danych?
To zależy 🙂 głównie od skali. Jeżeli skala projektu przetwarzania danych jest mała, to spokojnie można sobie poradzić z każdym z powyższych elementów. Oczywiście nie zawsze musi się to podobać – monitorowanie i administracja narzędzi, zamiast korzystanie z nich – ale jest to opcja. Jednak generalnie patrzyłbym na to bardziej zdroworozsądkowo.
Tak jak wspominałem już wcześniej IT jest szeroką dziedziną, którą można podzielić na wiele grup. Podobnie jest z inżynierią danych, którą spokojnie możemy podzielić.
Podział Inżynierii Danych na Dziedziny
Architektura Systemu
Świat nie stoi w miejscu, praktycznie każdego tygodnia, możemy usłyszeć o nowych narzędziach lub nowych usługach dostępnych u jednego z dostawców rozwiązań chmurowych. Nadążenie za nowinkami, testowanie, sprawdzanie i weryfikacja narzędzi w połączeniu z normalną codzienną prac, może być dość trudna. Warto rozważyć rolę, której głównym celem będzie jak najlepszy dobór narzędzi i projekt systemu do problemu, który chcemy rozwiązać.
To nie znaczy, że Ty jak chcesz skupić się na przetwarzaniu danych i logice biznesowej masz się zamknąć w piwnicy 🙂 Poświęcajmy czas na naukę i odkrywanie nowych rzeczy, to jest jasne. Jednak spójna wizja, doskonalenie procesu i podejścia zastosowane w rozwiązaniu zagwarantuje większy sukces.
Niezawodność narzędzi i komponentów
Narzędzia czy technologie, z których będziesz na co dzień korzystać, mają swoje cechy, wymagania i zdarza się, że czasami mogą się zepsuć. Technologie jak Hadoop, Apache Spark, Apache Airflow, czy dowolne inne nie są zarządzane przez niewidzialną rękę administratora. Ktoś je musi zainstalować, odpowiednio skonfigurować i monitorować zużycie zasobów, czy przypadkiem SELECT * nie dobija maszyny na której pracuje.
Takie zadanie jest nietrywialne, czasochłonne i często wymagania łączenia wielu dziedzin. Od dobrej znajomości systemów operacyjnych, przez technologie konteneryzacja czy wirtualizacji, przez warstwy sieciowe, po procesu identyfikacji tożsamości i dostępu do zasobów.
I znowu nie chodzi o to, że Ty masz siedzieć w złotej klatce i w ogóle się tym nie interesować. Jeżeli korzystasz z danej technologii, to co najmniej przyzwoicie byłoby wiedzieć jaka jest dla niej architektura (tzn. z jakich komponentów korzysta, żebyś Ty mógł / mogła z niej korzystać), jakie są najczęstsze problemy i jak można je zdiagnozować.
Przetwarzanie Danych
No i mamy mięsko – przetwarzanie danych.
- Jak wiele źródeł danych połączyć razem i wyciągnąć z tego informację biznesową?
- W jaki sposób zadbać o jakość procesów przetwarzania i samych danych?
- Jak dopilnować by dane były dostępne tak szybko jak to możliwe?
Na te i wiele innych pytań odpowiada właśnie inżynieria danych.
To nie tylko przygotowywanie odpowiednich procesów przetwarzania danych, ale również dbanie o jakość, powtarzalność i jak najlepsze rozwiązanie potencjalnych pytań biznesowych.
Tutaj możesz, pisać wszystko ręcznie, albo możesz korzystać z graficznych interfejsów użytkownika. Nierzadko, trzeba będzie podyskutować z ekspertami od systemów źródłowych, żeby ustalić strukturę, najlepszy sposób pobierania danych czy ich jakość w kontekście tego co docelowy klient chce otrzymać. Od Ciebie też będzie zależeć to czy warstwa analityczna / wizualizacyjna, będzie miała więcej pracy po swojej stronie, przy np. budowaniu i tworzeniu metryk biznesowych, czy może uda się to skonsolidować w warstwie danych i modelu danych.
Analityka i Wizualizacja
To czy analitykę i wizualizację zrobimy częścią procesu przetwarzania danych, to rzecz umowna. Ja osobiście jestem zdania, że powinna to być osobna część procesu, która mocno współpracuje i z klientami biznesowymi ale również z osobami odpowiedzialnymi za dostarczenie rzetelnych danych w takiej formie w jakiej to zostało ustalone.
Jako osoba znająca świetnie biznes i kluczowe problemy, nie muszę koniecznie wiedzieć, że dane sprzedażowe pochodzą z 8 różnych systemów źródłowych, o takich a nie innych strukturach. Raczej wolałbym się skupić na jak najtrafniejszej odpowiedzi na problem biznesowy. To będzie związane z rozmową nt. dobrego sposobu dostarczenia danych (np. zagregowanie danych do pewnego poziomu), sensownego ich odświeżania (może dane nie są potrzebne z dokładnością do X sekund), jakości danych (czyli tego czego spodziewamy się na wyjściu i co zrobić w sytuacji, gdy tego nie mamy) ale również (a może przede wszystkim) na przygotowaniu warstwy analitycznej / wizualizacji danych, żeby odbiorca mógł swobodnie z nią pracować.
Spróbujmy sobie nazwać role w tych grupach. Tytuły są umowne, jak już wspominałem wcześniej wielkiego znaczenia nie mają, ale dadzą nam łatwiejsze kojarzenie opisanych wyżej grup :
- Architektura: Data Architect
- Narzędzia, procesy, niezawodność: Data Reliability Engineer / DevOps Engineer (Data Tools)
- Przetwarzanie / Inżynieria danych: Data Engineer
- Analityka, wizualizacja: Data Analyst / Data Visualization Specialist / Business Intelligence Developer
Jakie „technologie” dotyka każda z ról?
Jeżeli spodziewasz się, że ładnie sobie tutaj wydzielimy technologie względem ról, no to Cię chyba zaskoczę. Technologie same w sobie nie mają wielkiego znaczenia, zmieniają się co jakiś czas i w zasadzie będą wspólne dla każdej z ról z małymi wyjątkami.
Co to znaczy, że będą wspólne dla każdej z ról? To znaczy tylko (albo aż) tyle, że baza danych będzie istotna zarówno dla architekta, devops-a, inżyniera danych jak i analityka. Jednak dla każdej z tych osób będzie istotna w innym kontekście. Kontekst ten to może być fakt jakie są limity danego produktu. Z perspektywy architekta (konkretny system operacyjny, brak możliwości konteneryzacji etc.). Dla inżyniera danych może to być fakt, czy jest jakiś istotny limit przy przetwarzaniu danych dla danego produktu / technologii itp.
Jednak, żeby nie być gołosłownym, we wstępie obiecałem Ci przedstawić „hot” technologie to spróbujmy:
- Język programowania (w zależności od konkretnych technologii): Python, SQL
- Kolejki wiadomości: Apache Kafka
- Przepływy danych: Apache Airflow
- „Ogólne” przeznaczenie: Apache Spark (strumieniowanie, SQL, przetwarzanie w pamięci)
- Bazy danych: PostgreSQL, Redis, Cassandra, Neo4j
- Usługi dostawców chmurowych, np. hurtownie danych: Snowflake (hurtownia danych w chmurze w oparciu o infrastrukturę wybranego dostawcy AWS / Azure / Google Cloud) lub Amazon Redshift, Google Big Query, Azure Synapse Analytics
- Inne: Docker (konteneryzacja), Jenkins (automatyzacja procesów), Kubernetes (słowo klucz musi paść w porządnym artykule, a tak serio do zarządzania serwisami),
- Analityka / Wizualizacje: Qlik Sense
Wybacz mi, ale nie będę opisywał każdej z tych technologii. Google na pewno przyjdzie Ci w tej kwestii z pomocą. Technologie powyżej to jest tylko mój czysto subiektywny wybór – nie mam z tego żadnych $. Jeżeli pracujesz z innymi technologiami w obszarach wymienionych powyżej, super na pewno też spełniają swoje zadanie.
Podsumowanie
Do brzegu Krzyśku do brzegu, czas powoli podsumowywać. W tym artykule pokazałem Ci moją drogę od skrobania SELECT-ów do roli Data Engineer. Jednak czy sama nazwa roli jest tutaj kluczem? Chciałbym, żeby po przeczytaniu tego tekstu wybrzmiała odpowiedź – nie.
Ważniejszy jest cel, a inżynieria danych ma jeden (no może nie jeden, ale ten najbardziej istotny).
Dostarczyć dane w taki sposób, by można było na ich podstawie podjąć akcję (i przy okazji żeby nie czekać tygodnia na te dane).
Wiesz, już że grup czy elementów pracy z danymi jest całkiem sporo, technologii jeszcze więcej.
Żeby do końca nie zagubić się w gąszczu tych elementów, warto zwrócić uwagę na rzeczy podstawowe:
Systemy źródłowe dla naszego projektu – warto poznąc ich strukturę i architekturę
– No co, przecież biorę SELECT * i pakuję do hurtownii …
– 320 atrybutów w tabeli źródłowej, 300 nie używanych w źródle bo kupili produkt z pudełka i nie wykorzystują …
– OK
Efektywne sposoby przechowywania danych – dopasowne do potrzeb projektu (miej na uwadzę fakt, że nie wszystkie dane potrzebujesz cały czas, a storage mimo, że jest stosunkowo tani, to jednak generuje koszty);
– Ale co się przejmujesz, storage jest tani
– koszt S3 – $0.023 per GB / miesięcznie, Glacier – $0.004 per GB / miesięcznie, mamy 50 TB danych historycznych, których nie odpytujemy 50 * 1024 * 0.023 – 1177,6 $ vs 50 * 1024 *0,004 – 204,8 $, dawaj 1k$ z wypłaty jak tani storage
Znajomość narzędzi, które pomagają w pracy – fajnie, że wiesz jak się pracuje w danym narzędziu, a czy wiesz też jakie problemy mogą Cię spotkać po drodzę, co może pójść nie tak lub na co zwracać uwagę?
– No ale co, że serwer padł, to co to moja wina? To przecież in-memory jest … to w pamięci ma działać
Logiczne i czytelne sposoby przetwarzania danych – kroków przy przetwarzaniu danych może być wiele, ale jeżeli nie potrafisz jasno określić drogi od źródła do końcowego wyniku, to chyba gdzieś coś zostało za bardzo skomplikowane
– No i widzisz tutaj bierzemy ze źródła. Dalej mamy narzędzie A do warstwy „stagingowej”. Później transformacja w procedurze, dalej ładujemy dane do narzędzia BI. Tam 2 transformacje no i jest ten wykres
- Hmm .. to jak jest wyliczana ta metryka Różnica Sprzedaży Miesiąc do Miesiąca
- No to przecież Ci powiedziałem …
Praca z danymi to najczęściej praca w zespole – egoistyczne podejście do pracy, może być dobre na krótką chwilę. W zespole jednak szykujemy się na maraton;
– Huehue tu sobie napiszę, szybki skrypcik w Go, zawsze się chciałem nauczyć.
- Andrzej, kto pisał ten skrypt do ładowania danych do wymiaru wolnozmiennego w Go? Jakiś błąd jest i nic z tego nie wiadomo …
Wiedza o tym jak działają twoje narzędzia i procesy oraz jaka jest jakość danych na każdym z etapów;
– Dlaczego w polu Region, mam wartość Polska, 6 razy i każdy element wygląda inaczej?
- No .. takie dane ze źródła przyszły …
Analityka, dzięki której nie trzeba się zastanawiać czy wyniki są prawidłowe i sprawdzać w innych systemach;
– Suma sprzedaży za ostatni kwartał wynosi 100 000$. W narzędziu zespołu B jest 96 699$ to czekaj, macie inne dane?
Tyle (albo aż tyle) tytułem odpowiedzi na pytanie czym jest inżynieria danych.
Chcesz być na bieżąco z nowymi postami?
Skorzystaj z poniższego formularza, aby dołączyć do newslettera Data Craze Weekly!