
DDL + INSERT dla TABEL używanych w pytaniach
PRODUCTS
CREATE TABLE IF NOT EXISTS products (
product_id SERIAL,
product_name varchar(500),
product_category varchar(250),
random_desc text
);
INSERT INTO products (product_name, product_category, random_desc)
SELECT 'Product '||floor(random() * 10 + 1)::int
, 'Category '||floor(random() * 10 + 1)::int
, left(md5(i::text), 15)
FROM generate_series(1, 1000) s(i);SALES
CREATE TABLE IF NOT EXISTS sales (
id SERIAL,
sales_date TIMESTAMP,
sales_amount NUMERIC(38,2),
sales_qty INTEGER,
discount NUMERIC(38,2),
product_id INTEGER
);
INSERT INTO sales (sales_date, sales_amount, sales_qty, product_id)
SELECT NOW() + (random() * (interval '90 days')) + '30 days'
, random() * 10 + 1
, floor(random() * 10 + 1)::int
, floor(random() * 100)::int
FROM generate_series(1, 10000) s(i);CONTACTS
CREATE TABLE IF NOT EXISTS contacts(
imie_nazwisko TEXT,
gender TEXT,
city TEXT,
country TEXT,
id_company INTEGER,
company TEXT,
added_by TEXT,
verified_by TEXT
);
INSERT INTO contacts VALUES
('Krzysztof, Bury', 'M', 'Kraków', 'Polska', 1, 'ACME', 'Person A', 'Person B')
, ('Magda, Kowalska', 'F', 'New York', 'USA', 2, 'CDE', 'Person C', 'Person A');UWAGA: Ta tabela celowo zawiera pewne błędy strukturalne (np. dotyczące normalizacji) ... sprawdź pytania.
Możesz użyć SQL Fiddle w przeglądarce do wykonywania zapytań online - TUTAJ
Kliknij na Pytanie, aby poznać odpowiedź.
Co oznacza SQL? Jakie są elementy języka zapytań do bazy danych? #podstawy #teoria
SQL (Structured Query Language) to język zapytań do bazy danych.
Język SQL można podzielić na kilka części:
- DDL - Data Definition Language - część języka SQL, odpowiedzialna za tworzenie, modyfikowanie lub usuwanie obiektów bazy danych, operacje takie jak CREATE, ALTER, DROP.
- DML - Data Manipluation Language - zestaw instrukcji SQL umożliwiający wykonywanie operacji INSERT, UPDATE, DELETE (dodawanie, aktualizowanie, usuwanie wierszy).
- DQL - Data Query Language - podstawa pobierania danych, czyli SELECT.
- DCL - Data Control Language - element umożliwiający dodawanie lub usuwanie uprawnień, GRANT / REVOKE.
- DTL / TCL - Data Transaction Language / Transaction Control Language - część odpowiedzialna za obsługę transakcji: COMMIT, ROLLBACK, SAVEPOINT.
Czym jest system zarządzania bazą danych (DBMS)? #podstawy #teoria
DBMS - Database Management System - to zbiór reguł (system) opisanych przez programy komputerowe, który umożliwia manipulowanie (zarządzanie) wartościami atrybutów kilku różnych typów encji, uporządkowanych w sensowny sposób (baza danych).
Czym jest DDL w kontekście SQL? #podstawy #teoria
DDL - Data Definition Language, jest elementem języka zapytań baz danych, którego celem jest tworzenie, modyfikowanie i usuwanie elementów struktury bazy danych - tabel, schematów, indeksów itp.
Kluczowe elementy składni obejmują operacje: CREATE, ALTER i DELETE.
Chociaż powyższe operacje są częścią standardu, ich dodatkowe elementy są implementowane w różny sposób przez różnych dostawców rozwiązań baz danych. Poniżej znajdują się przykładowe definicje instrukcji CREATE TABLE od różnych dostawców
CREATE TABLE:
Podaj jeden przykład użycia składni dla każdego elementu DDL. #podstawy #teoria
CREATE: CREATE TABLE sales ( id SERIAL );
ALTER: ALTER TABLE sales ADD COLUMN sales_amount NUMERIC(10,2);
DROP: DROP TABLE sales;Czym jest DCL w kontekście SQL. #podstawy #teoria
DCL (Data Control Language) to element języka zapytań baz danych, którego celem jest udzielanie i cofanie dostępu do obiektów bazy danych.
Kluczowe elementy składni obejmują następujące operacje: GRANT / REVOKE (DENY)
- GRANT - udziela dostępu do obiektów bazy danych
- REVOKE (DENY) - odmawia dostępu do obiektów bazy danych
Czym jest TCL w kontekście SQL. #podstawy #teoria
TCL (Transaction Control Language) - jest elementem języka zapytań baz danych, którego celem jest zarządzanie transakcjami w bazie danych.
Kluczowe elementy składni obejmują następujące operacje: COMMIT, ROLLBACK, SAVEPOINT.
- COMMIT - potwierdza transakcję i wszystkie wykonane w niej akcje.
- ROLLBACK - wycofuje transakcję i wszystkie wykonane w niej akcje, które wpływają na strukturę bazy danych i same dane.
- SAVEPOINT - zapisuje stan, do którego można się odwołać w ramach transakcji.
Jakie elementy struktury bazy danych możemy wyróżnić (elementy jako warstwy bazy danych, np. tabele, indeksy itp.)? #podstawy #teoria
Typowe elementy struktury bazy danych obejmują:
- schemat bazy danych
- tabele
- kolumny (atrybuty/pola)
- wiersze (rekord)
- klucze/ograniczenia
- widoki
- indeksy
- procedury/funkcje
Jakie są standardowe typy danych, które znasz - typy ogólne plus ich przybliżony podział - na podstawie bazy danych, z którą masz największe doświadczenie. #podstawy #teoria
Typy danych można podzielić na:
- alfanumeryczne
- numeryczne
- data i godzina
- prawda/fałsz (boolean)
- tablice
- binarne
- json/bson
- xml
Jakie są typowe ograniczenia atrybutów tabeli (kolumn)? #podstawy #teoria
- KLUCZ PODSTAWOWY - klucz podstawowy tabeli (relacja) - jeśli jest prosty, tj. jednoelementowy, jest ograniczeniem atrybutu. W przypadku złożonego klucza podstawowego będzie to ograniczenie relacji.
- NOT NULL / NULL - wartość nie może / nie może być niezdefiniowana
- UNIQUE - wartość musi być unikatowa w całej relacji
- SERIAL / AUTO_INCREMENT - atrybut jest typu numerycznego z automatycznym zwiększeniem wartości w polu, gdy wykonywana jest operacja INSERT
- DEFAULT wartość - domyślna wartość atrybutu
- CHECK warunek - ograniczenie domeny atrybutu, np. kolumna AGE z ograniczeniem CHECK > 14, tj. wartość atrybutu AGE musi być wyższa niż 14 w momencie wykonywania operacji INSERT
Czym jest transakcja bazy danych? #podstawy #teoria
To nic innego jak metoda używana przez aplikację do grupowania, odczytu i zapisu operacji w jedną jednostkę logiczną. Wynikiem transakcji jest jeden z dwóch stanów: Sukces (transakcja jest zatwierdzona) lub Niepowodzenie (transakcja jest anulowana lub wycofana).
Przyjrzyjmy się klasycznemu przykładowi transakcji: transakcji bankowej polegającej na wymianie środków między dwoma rachunkami, Rachunkiem A i Rachunkiem B. Właściciel Rachunku A chce przelać 100 zł na Rachunek B. Generalnie w tym przykładzie mamy dwa podejścia.
Podejście 1:
Operacja 1: Saldo Rachunku A = Saldo Rachunku A - 100 zł;
Operacja 2: saldo konta B = saldo konta B + 100 zł;
Podejście 2:
Operacja 1: saldo konta B = saldo konta B + 100 zł;
Operacja 2: saldo konta A = saldo konta A - 100 zł;
W rzeczywistości cała operacja jest nieco bardziej skomplikowana (są kontrole, zasady biznesowe i prawne banku itp.), ale idea jest ta sama. Jeśli wystąpi awaria podczas wykonywania operacji, mamy problem. Albo 100 zł wyparuje z konta A i nie pojawi się na koncie B, albo pojawi się na koncie B, ale saldo konta A nie zostanie zmienione. Z pomocą przychodzi transakcja, która obejmuje wykonanie operacji w jednym z podejść i gwarantuje: pomyślne wykonanie obu operacji (COMMIT) lub brak zmian w stanach obu kont (rollback/ROLLBACK)
BEGIN [TRANSACTION]
AccountStateA = AccountStateA - 100;
AccountBan = AccountB + 100;
END [TRANSACTION] (COMMIT)Czym jest ACID w relacyjnych bazach danych? #podstawy #teoria
A.C.I.D. gwarantuje bezpieczeństwo w relacyjnych bazach danych.
Jest to zbiór mechanizmów, które mają na celu zapewnienie pewnej odporności na błędy i problemy relacyjnych baz danych.
A.C.I.D. to akronim 4 takich gwarantów:
- A (Atomicity) - atomowość
- C (Consistency) - spójność
- I (Isolation) - izolacja
- D (Durability) - trwałość
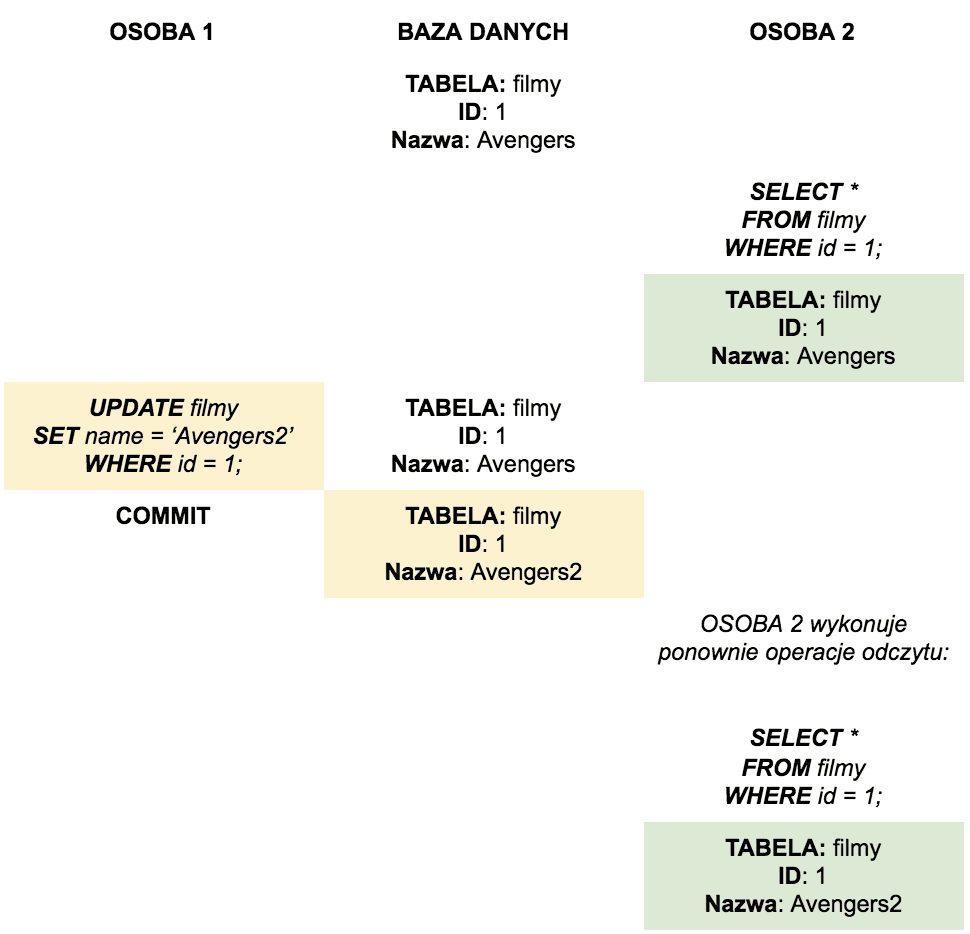
Czym jest kontrola współbieżności w bazach danych? Jakie znasz problemy związane z kontrolą współbieżności? #podstawy #teoria
Kontrola współbieżności — zestaw funkcji udostępnianych przez bazę danych, umożliwiający wielu użytkownikom równoczesny dostęp do danych i wykonywanie operacji na niczym.
Problemy z kontrolą współbieżności:
- Dirty Read — odczyt „zaktualizowanych” (UPDATE) danych przed ich zaakceptowaniem (COMMIT) przez inną transakcję.
- Phantom Read — pojawienie się nowych rekordów / lub zniknięcie istniejących, podczas gdy to samo zapytanie zostanie uruchomione po wykonaniu 1 równoważnego zapytania.
- Non-Repeatable Read — powoduje, że rekordy z poprzedniego zapytania pojawiają się w zmienionej formie, gdy zapytanie jest ponownie wykonywane.
- Non-Repeatable Read — powoduje, że oczekująca transakcja zostaje nadpisana inną transakcją, wcześniej zainicjowaną przez inną transakcję.
Czym jest LOCK w bazie danych? #podstawy #teoria
LOCK występuje, gdy dwie transakcje czekają na siebie nawzajem, aby zwolnić zasoby, a przynajmniej jedna z nich nie może kontynuować swojej operacji.
T1: UPDATE products SET product_name = 'Product 999' where product_name = 'Product 1';
T2: UPDATE products SET product_name = 'Product 998' where product_name = 'Product 2';
T1: UPDATE products SET product_name = 'Product 001' where product_name = 'Product 1';
T2: UPDATE products SET product_name = 'Product 991' where product_name = 'Product 2';Te same wiersze „Product1” i „Product2” są modyfikowane w różnych transakcjach za pomocą COMMIT.
Czym jest izolacja w relacyjnych bazach danych? #podstawy #teoria
Izolacja oznacza, że jednocześnie wykonywane transakcje są od siebie odizolowane — nie mogą na siebie wpływać. Jest to szczególnie ważne w przypadku dostępu do tego samego zasobu (tej samej tabeli), w przypadku dostępu do różnych obiektów konflikt nie wystąpi.
Inna definicja to taka, w której izolacja jest gwarancją, że równoległe wykonanie transakcji pozostawi bazę danych w stanie, jakby operacje zostały wykonane w sposób sekwencyjny.
Warto pamiętać, że izolacja jest wymianą integralności bazy danych kosztem wydajności.
Przykład:
Czym są poziomy izolacji transakcji i co o nich wiesz? #podstawy #teoria
Poziomy izolacji transakcji to standardy/podejścia do radzenia sobie z problemami współbieżności transakcji.
- Read Uncommited< — najmniej restrykcyjny, zezwala na 3 typy odczytów (Dirty, Phantom i Non-Repeatable Reads). Prawdopodobnie nieużywany w komercyjnych bazach danych.
- Read Commited — umożliwia zapytaniu dostęp do danych, które zostały zaakceptowane (COMMIT). Brak odczytów brudnych, zezwala na odczyty fantomowe i niepowtarzalne. Najczęściej używany poziom izolacji.
- Repeatable Read — gwarantuje spójność odczytów. Umożliwia tylko odczyt fantomowy.
- Serializable - najbardziej restrykcyjny poziom izolacji (nie zezwala na Dirty, Non-Repeatable i Phantom Reads). Każda transakcja jest traktowana tak, jakby była jedyną transakcją mającą miejsce w bazie danych w danym momencie.
Jaka jest różnica między poziomami izolacji Read Committed i Serializable? #podstawy #teoria
- Read Committed — dobre rozdzielenie spójności i współbieżności. Dobre dla standardowych aplikacji OLTP (OnLine Transaction Processing), w których występuje wiele równoczesnych, krótkotrwałych transakcji, z których rzadko występują konflikty. Lepsza wydajność.
- Serializable — dobre dla baz danych z wieloma spójnymi transakcjami. Niższa wydajność z powodu wyższego blokowania. Używane głównie w bazach danych z transakcjami tylko do odczytu, które działają przez długi czas (zapytania analityczne, patrz OLAP — OnLine Analytical Processing).
Czym jest normalizacja bazy danych? #podstawy #teoria
Normalizacja bazy danych to technika organizacji danych w bazie danych, jest to systematyczne, metodyczne podejście polegające na „rozbijaniu” tabel w celu wyeliminowania powtórzeń i niepożądanych cech dodawania, usuwania i aktualizowania wierszy.
Dwa główne cele standaryzacji:
- Przedstawianie faktów ze świata rzeczywistego w sposób zrozumiały;
- Zmniejszanie nadmiarowego przechowywania faktów i zapobieganie nieprawidłowym lub niespójnym danym;
INSERT — problemy z brakiem normalizacji
Kolumna miasta (CITY) w tabeli CONTACTS jest dobrym przykładem do rozważenia problemów nienormalizacyjnych w kontekście operacji INSERT.
Dodając 100 kontaktów z Poznania przypisujemy wszystkim rekordom te same informacje tekstowe. Z drugiej strony, jeśli kontakt nie podał informacji o mieście (nie jest to wymagane), będziemy musieli wpisać w tym polu niezdefiniowaną wartość NULL.
UPDATE - problemy z brakiem normalizacji
Kolumna COMPANY w tabeli CONTACTS jest dobrym przykładem do rozważenia problemów braku normalizacji w kontekście operacji UPDATE.
Jeśli wiele kontaktów pracuje dla tej samej firmy - ACME - i ta firma zmienia nazwę lub znika z rynku. Wszystkie rekordy będą musiały mieć zaktualizowaną wartość, pominięcie kontaktu i pozostawienie go z wartością ACME spowoduje niespójność danych.
DELETE - problemy z brakiem normalizacji
Załóżmy, że tabela CONTACTS jest jedynym miejscem, w którym przechowujemy informacje o mieście (CITY). Jeśli z jakiegoś powodu usuniemy wszystkie kontakty z Poznania, nie będziemy mogli odwołać się do tej wartości w przypadku innych zapytań.
Jakie formy normalne znasz? Wymień je i podaj krótki opis. #podstawy #teoria
- 1 Postać normalna (1NF) - Tabela musi być relacją i nie może zawierać żadnych powtarzających się grup.
- 2 Postać normalna (2NF) - Tabela jest w 1. postaci normalnej i ma dokładnie jeden klucz kandydujący (klucz kandydujący, który jest tym samym kluczem podstawowym) i nie jest kluczem złożonym (składa się z 1 kolumny).
- 3 Postać normalna (3NF) - W 3. postaci normalnej wszystkie atrybuty niekluczowe muszą zależeć od klucza danej tabeli.
- 3.5 / BCNF Postać normalna Boyce'a-Codda (BCNF) - W postaci normalnej Boyce'a-Codda wszystkie atrybuty, w tym te należące do klucza, muszą zależeć od klucza danej tabeli.
- 4 Postać normalna (4NF) - Każda tabela, która jest mający na celu reprezentowanie wielu relacji wiele-do-wielu narusza zasady czwartej postaci normalnej.
- 5 Postać normalna (5NF) — każda tabela spełniająca kryteria postaci normalnej Boyce'a-Codda i niezawierająca złożonego klucza podstawowego znajduje się w 5. postaci normalnej.
- 5.5 Postać normalna klucza domeny (DKNF) — każde ograniczenie tabeli musi być logiczną konsekwencją ograniczeń domeny tabeli i ograniczeń klucza.
- 6 Postać normalna (6NF) — tabela znajduje się w 6. postaci normalnej, jeśli oprócz atrybutu, który jest również kluczem podstawowym, ma maksymalnie 1 dodatkowy atrybut.
Jak mogłaby wyglądać normalizacja tabeli CONTACTS? #podstawy #teoria
1NF - oddzielamy pole NAME_SURNAME.
| NAME| SURNAME | GENDER | CITY | COUNTRY | ID_COMPANY | COMPANY | ADDED_BY | VERIFIED_BY |
|---|---|---|---|---|---|---|---|---|
| Krzysztof | Bury | M | Krakow | Poland | 1 | ACME | PersonA | PersonB |
| Magda| Kowalski | F | New York | USA | 2 | CDE | PersonC | OsobaA |
2NF - wyodrębniamy tabelę GENDER na podstawie kolumny GENDER z tabeli CONTACTS.
CONTACTS
| NAME| SURNAME | CITY | COUNTRY | ID_COMPANY | COMPANY | COMPANY | ADDED_BY | VERIFIED_BY |
|---|---|---|---|---|---|---|---|
| Krzysztof | Bury | Krakow | Poland | 1 | ACME | PersonA | PersonB |
| Magda| Kowalski | New York | USA | 2 | CDE | PersonC | PersonA |
GENDER
| NAME| GENDER |
|---|---|
| Krzysztof | M |
| Magda | F |
3NF - oddzielamy tabelę COMPANY od tabeli CONTACTS na podstawie kolumn ID_COMPANY i COMPANY.
CONTACTS
| NAME| SURNAME | CITY | COUNTRY | ID_COMPANY | ADDED_BY | VERIFIED_BY |
|---|---|---|---|---|---|---|
| Krzysztof | Bury | Krakow | Poland | 1 | PersonA | PersonB |
| Magda| Kowalski | New York | USA | 2 | PersonC | PersonA |
GENDER
| NAME| GENDER|
|---|---|
| Krzysztof | M |
| Magda | F |
COMPANY
| ID_COMPANY | COMPANY |
|---|---|
| 1 | ACME |
| 2 | CDE |
BCNF - tworzymy nową tabelę CITY_COUNTRY na podstawie kolumn CITY i COUNTRY z tabeli CONTACTS.
CONTACTS
| NAME| SURNAME | CITY | ID_COMPANY | ADDED_BY | VERIFIED_BY |
|---|---|---|---|---|---|---|
| Krzysztof | Bury | Krakow | 1 | PersonA | PersonB |
| Magda| Kowalski | New York | 2 | PersonC | PersonA |
GENDER
| NAME| GENDER |
|---|---|
| Krzysztof | M |
| Magda | F |
COMPANY
| ID_COMPANY | COMPANY |
|---|---|
| 1 | ACME |
| 2 | CDE |
CITY_COUNTRY
| CITY | COUNTRY |
|---|---|
| Krakow | Poland |
| New York | USA |
4NF - tworzymy nową tabelę CONTACTS_VERIFIED_BY i CONTACTS_ADDED_BY na podstawie kolumn VERIFIED_BY i ADDED_BY z tabeli CONTACTS.
CONTACTS
| NAME| SURNAME | CITY | ID_COMPANY |
|---|---|---|---|
| Krzysztof | Bury | Krakow | 1 |
| Magda | Kowalski | New York | 2 |
GENDER
| NAME| GENDER |
|---|---|
| Krzysztof | M |
| Magda | F |
COMPANY
| ID_COMPANY | COMPANY |
|---|---|
| 1 | ACME |
| 2 | CDE |
CITY_COUNTRY
| CITY | COUNTRY |
|---|---|
| Krakow | Poland |
| New York | USA |
CONTACTS_VERIFIED_BY
| CONTACT_NAME | VERIFIED_BY |
|---|---|
| Krzysztof | PersonB |
| Magda | PersonA |
CONTACTS_ADDED_BY
| CONTACT_NAME | ADDED_BY |
|---|---|
| Krzysztof | PersonA |
| Magda | PersonC |Czym jest widok (view) w SQL? #podstawy #teoria
Widok to trwała definicja tabeli pochodnej (wynik zapytania SELECT), która jest przechowywana w bazie danych.
W SQL tabela utworzona za pomocą zapytania CREATE TABLE jest nazywana tabelą bazową. Formalnie wynik każdego zapytania SELECT nazywamy tabelą pochodną. Tabele używane do definiowania widoku są nazywane tabelami bazowymi.
Syntax:
CREATE OR REPLACE VIEW view_name AS SELECT ...
DROP VIEW view_name;Właściwości widoku:
- nie przechowuje danych — definicja widoku jest zapisywana w bazie danych. Sam widok jest tylko interfejsem odczytu danych;
- zawsze wyświetla bieżące dane — baza danych zawsze odtwarza bieżące dane z tabel źródłowych użytych do zbudowania widoku;
Widoki są używane do:
- tworzenia dodatkowego poziomu zabezpieczeń tabeli poprzez ograniczenie dostępu do określonych kolumn lub wierszy tabeli bazowej;
- ukrywania złożoności danych — gdy definicja widoku jest złożonym zapytaniem SELECT, samo zapytanie widoku jest widoczne jako proste zapytanie;
- pokazywania danych z innej perspektywy — na przykład widok może być użyty do zmiany nazwy kolumny bez zmiany rzeczywistych danych przechowywanych w tabeli;
Jaka jest różnica między widokiem a widokiem zmaterializowanym (VIEW vs MATERIALIZED VIEW)? #podstawy #teoria
Widok zmaterializowany, w przeciwieństwie do widoku, jest definicją zapytania SELECT, która po utworzeniu (i z określoną częstotliwością) zapisuje wyniki zapytania do obiektu bazy danych, tabeli.
Dane z definicji widoku zmaterializowanego są odświeżane zgodnie z ustalonym harmonogramem (ustawionym w definicji widoku zmaterializowanego).
Z reguły w przypadku złożonych zapytań, gdy zapytanie dotyczy zwykłego widoku, należy wykonać całe złożone zapytanie. W przypadku widoku zmaterializowanego dane są natychmiast dostępne z aktualizacją równą ostatniemu odświeżeniu widoku zgodnie z harmonogramem.
Czym są systemy transakcyjne OLTP? #podstawy #teoria
OLTP - OnLine Transaction Processing - to system skoncentrowany na krótkoterminowych, szybkich transakcjach.
- źródło danych: dane operacyjne; Systemy OLTP są pierwotnym źródłem danych;
- cel danych: obsługa i kontrola podstawowych procesów biznesowych;
- co jest w danych: aktualny stan procesów biznesowych;
- Operacje wstawiania/aktualizowania: krótkie i szybkie operacje wstawiania/aktualizowania inicjowane przez użytkowników końcowych;
- zapytania: stosunkowo proste i standardowe zapytania, zwykle zwracające kilka rekordów;
- czas przetwarzania: zwykle bardzo szybki;
- potrzebne miejsce: dane mogą zajmować stosunkowo mało miejsca, jeśli dane historyczne są archiwizowane;
- struktura bazy danych: wysoce standaryzowana z dużą liczbą tabel;
- kopiowanie i odzyskiwanie danych: obowiązkowe kopiowanie danych; dane operacyjne są krytyczne dla prowadzenia działalności gospodarczej, utrata danych zwykle skutkuje dużymi stratami finansowymi i odpowiedzialnością prawną;
Typowymi przykładami są zasadniczo większość systemów wsparcia produkcji przedsiębiorstwa - systemy ERP/CRM (z wyjątkiem modułów analitycznych).
Inne przykłady: system bankowy, który obsługuje odczytywanie i modyfikowanie sald rachunków klientów; systemy finansowe i księgowe.
Czym są systemy analityczne OLAP? #podstawy #teoria
OLAP - Online Analytical Processing - to systemy skoncentrowane na dostarczaniu modelu analitycznego, tj. przygotowywaniu danych i optymalizowaniu modelu tak, aby procesy analityczne były priorytetem.
- źródło danych: dane skonsolidowane; dane źródłowe systemów OLAP pochodzą z różnych baz danych/źródeł danych;
- cel danych: pomoc w planowaniu, rozwiązywaniu problemów i podejmowaniu decyzji strategicznych;
- co zawierają dane: wielowymiarowe spojrzenie na różne rodzaje działalności biznesowej, stan obecny i historię;
- Operacje wstawiania/aktualizowania: cykliczne, długotrwałe odświeżanie danych, zwykle przy użyciu plików wsadowych;
- zapytania: zapytania, które są często bardzo złożone i wymagają agregacji;
- czas przetwarzania: zależy od ilości przetwarzanych danych;
- potrzebna przestrzeń: duża ilość miejsca potrzebna ze względu na istnienie zagregowanych i historycznych danych;
- struktura bazy danych: zwykle zdenormalizowana z niewielką liczbą tabel; stosowane schematy gwiazd i/lub płatków śniegu;
- kopia zapasowa i odzyskiwanie danych: oprócz kopii zapasowych, ponowne ładowanie danych z systemów źródłowych może być uważane za metodę odzyskiwania danych;
Typowym przykładem są magazyny danych lub ogólnie systemy tworzone i optymalizowane pod kątem procesów analitycznych.
OLTP vs OLAP, jaka jest różnica między systemami? #podstawy #teoria
OLTP:
- duża liczba prostych zapytań (transakcji)
- systemy zoptymalizowane pod kątem szybkiego dodawania, usuwania i modyfikowania pojedynczych rekordów
- zwykle utożsamiane z tradycyjnymi relacyjnymi bazami danych
- niewielka liczba zapytań, często dotyczących wielu elementów biznesowych
- systemy zoptymalizowane pod kątem szybkiego odczytu informacji analitycznych (z zagregowanych danych)
- zwykle powiązane z magazynami danych, wspierającymi decyzje biznesowe firmy (systemy Business Intelligence) i „bardzo duże” ilości danych
- przetwarzanie danych (do najnowszych informacji) może trwać minuty lub godziny — nie zakładamy, że dane są aktualne
Czym są i jakie typy funkcji agregujących znasz w SQL? #podstawy #teoria
Funkcje agregujące w SQL to grupa funkcji, które, jak sama nazwa wskazuje, służą do uzyskania wyniku operacji dla grupy rekordów, zgodnie z wybranymi kluczami grupy.
Przykładem może być wartość sprzedaży podzielona na kategorie produktów.
Najczęściej używane funkcje agregujące:
- SUM() - sumowanie
- AVG() - średnia
- COUNT() - zliczanie wystąpień
- MIN() / MAX() - minimum / maksimum
- STDEV() - odchylenie standardowe
Co to są i jakie rodzaje funkcji analitycznych znasz w SQL? #podstawy #teoria
Funkcje analityczne to określone rodzaje funkcji SQL, które dostarczają wynik dla danego wiersza w kontekście wierszy sąsiadujących (poprzedzających/następujących) po wierszu. Używamy tego typu funkcji, na przykład, do „rankingu” danych lub obliczania stanów (bilansowania).
Najczęściej używane funkcje analityczne:
- ROW_NUMBER() OVER()
- DENSE_RANK() / RANK() OVER()
- SUM() OVER()
- LEAD() / LAG() OVER()
Jaka jest różnica między składnią WHERE i HAVING? #podstawy #teoria
Gdy nie są używane w kontekście GROUP BY, są zasadniczo równoważne.
Jednak ich rzeczywiste zastosowanie ma miejsce, gdy dane są grupowane.
- Warunek WHERE filtruje rekordy z wyniku przed wykonaniem grupowania.
- Warunek HAVING filtruje rekordy z wyniku po wykonaniu grupowania
Co robią polecenia DELETE i TRUNCATE? Jakie są między nimi różnice? #podstawy #teoria
Oba polecenia służą do usuwania wierszy z tabeli, ale istnieją między nimi pewne subtelne różnice.
DELETE to operacja DML (Data Manipulation Language), która działa na poziomie wiersza tabeli. Za jej pomocą możemy usunąć wszystkie wiersze lub jeden konkretny wiersz (dodając WHERE).
DELETE FROM TABLE_NAME WHERE …TRUNCATE TABLE TABLE_NAME …Transakcyjne
- DELETE, podobnie jak INSERT lub UPDATE, może zostać zaakceptowane (COMMIT) lub wycofane (ROLLBACK).
- TRUNCATE w niektórych systemach baz danych ma tzw. „niejawne COMMIT”. Oznacza to, że operacja COMMIT jest wykonywana przed i po operacji TRUNCATE bez potrzeby dodatkowego wykonania COMMIT.
Uwaga: Powyższe dotyczy np. Oracle, w przypadku SQL Server lub PostgreSQL operację TRUNCATE można wycofać (ROLLBACK).
Odzyskiwanie miejsca
- DELETE nie odzyskuje miejsca po usunięciu wierszy. Potrzebna jest dodatkowa operacja VACUUM.
- TRUNCATE odzyskuje miejsce po usunięciu wierszy.
- DELETE blokuje określone wiersze tabeli, które są usuwane.
- TRUNCATE blokuje całą tabelę.
- DELETE wykonuje operacje wyzwalacza (trigger) AFTER/BEFORE DELETE.
- TRUNCATE nie wykonuje wyzwalaczy (trigger).
Są to jednak dość specyficzne kwestie, jeśli chcesz zagłębić się w temat, zapoznaj się ze szczegółową dokumentacją systemów, w których pracujesz.
Jaki jest cel opcji CASCADE podczas operacji DELETE w SQL? #podstawy #teoria
Gdy relacja klucza obcego jest zdefiniowana między tabelami i istnieją rekordy powiązane z tą relacją, nie będzie możliwe wykonanie operacji DELETE na danych tabeli, do której utworzono relację.
Baza danych poinformuje nas, że w relacji między tabelami A i B są rekordy, które chcemy usunąć. Aby wykonać tę operację, musimy najpierw usunąć rekordy powiązane z tabelą B lub użyć opcji CASCADE.
Opcja CASCADE usuwa wszystkie wiersze z tabeli A i wszystkie powiązane wiersze z tabeli B, które mają relację klucza obcego między tabelami.
Jaki jest cel opcji CASCADE podczas operacji DROP w SQL? #podstawy #teoria
Gdy istnieje relacja między obiektami bazy danych, tj. obiekt B zależy od obiektu A, np. widok B w tabeli A, wykonanie operacji DROP na obiekcie A nie będzie możliwe.
Baza danych poinformuje nas, że istnieje połączenie w relacji między obiektem A i B. Jeśli chcemy usunąć obiekt A, musimy najpierw usunąć obiekt B lub użyć opcji CASCADE.
Opcja CASCADE usuwa obiekt zdefiniowany do usunięcia i wszystkie obiekty, które używają / są tworzone z obiektu A.
Co to jest operator IN w SQL i do czego służy? #podstawy #teoria
IN to operator logiczny używany w części WHERE zapytania. Pozwala sprawdzić, czy wartość z danej kolumny/funkcji istnieje/jest równa dowolnej wartości z listy.
Porównywanie wartości z listą jest bardzo wygodne, przykładem może być użycie takiej listy na warstwie prezentacji (stronie internetowej), a następnie wysłanie żądania do bazy danych, aby wyświetlić tylko te wyniki, które użytkownik wybrał.
Operator IN jest zasadniczo równoważny zapisaniu wielu warunków OR dla tej samej kolumny i różnych wartości. Dlatego warto go użyć w takim przypadku, choćby ze względu na czytelność.
Jednym z pytań, które powinno ci przyjść do głowy jest: "ile wartości mogę użyć w IN?".
Odpowiedź nie jest jasna i będzie zależeć od bazy danych.
W SQL Server „dużo” — WIĘCEJ TUTAJ
W przypadku bazy danych Oracle będzie to „bardzo mało” (1000 według tego artykułu WIĘCEJ TUTAJ)
Pamiętaj, że to, że możemy używać wielu wartości w operatorze IN, nie oznacza, że powinniśmy. W tym przypadku stosujemy dużo operacji OR, a nie jest to najbardziej efektywne podejście do wykonywania zapytań.
Do czego służą funkcje CEIL i FLOOR? Wyjaśnij zasadę działania obu funkcji na przykładzie. #podstawy #teoria
Funkcje CEIL i FLOOR pozwalają zaokrąglić daną liczbę do liczby całkowitej.
Prawdopodobnie pamiętasz zagadnienia zaokrąglania z matematyki. Jeśli mamy liczbę 254 i chcemy ją zaokrąglić do najbliższej dziesiątki, otrzymamy liczbę 250. Jeśli mamy na przykład 255, otrzymamy 260.
CEIL (lub CEILING) i FLOOR. W „wolnym” tłumaczeniu: ceiling i floor, i już możesz zgadnąć, co to jest. Funkcja CEIL (CEILING) zwraca najmniejszą liczbę całkowitą większą lub równą wartości podanej na wejściu.
SELECT 8.28 as output_value,
CEILING(8.28) as positive_value,
CEILING(-8.28) as negative_value;
Wynik:
wartość_wyjściowa: 8,28
wartość_dodatnia: 9
wartość_ujemna: -8SELECT 8.28 as output_value,
FLOOR(8.28) as positive_value,
FLOOR(-8.28) as negative_value;
Wynik:
wartość_wyjściowa: 8,28
wartość_dodatnia: 8
wartość_ujemna: -9Czym jest funkcja ROUND? Jaka jest różnica między wynikiem ROUND a CEIL/FLOOR. #podstawy #teoria
Funkcja ROUND, podobnie jak CEIL i FLOOR, umożliwia zaokrąglanie wartości. Jednak zaokrąglanie jest bardziej „matematyczne” (tj. jeśli jest to 5, jest to zaokrąglenie w górę, a jeśli jest to mniej niż 5, jest to zaokrąglenie w dół).
Ponadto za pomocą tej funkcji można określić, do ilu miejsc po przecinku ma zostać zaokrąglona wartość wyjściowa.
SELECT 8.49 as output_value,
FLOOR(8.28) as floor_value,
CEIL(8.28) as cel_value,
ROUND(8.49) as rounded_value
wartość_wyjściowa: 8,49
wartość_podłogowa: 8
wartość_docelowa: 9
wartość_zaokrąglona: 8 (brak zaokrąglenia po przecinku, domyślnie 0 miejsc dziesiętnych)
SELECT 8.51 as output_value,
FLOOR(8.51) as floor_value,
CEIL(8.51) as cel_value,
ROUND(8.51) as rounded_value
wartość_wyjściowa: 8,49
wartość_podłogowa: 8
wartość_docelowa: 9
wartość_zaokrąglona: 9 (brak zaokrąglenia po przecinku, domyślnie 0 miejsc dziesiętnych)Zależy to od używanego silnika bazy danych.
W przypadku PostgreSQL typy zwracane dla funkcji to:
- CEIL — taki sam typ jak typ wejściowy
- FLOOR — taki sam typ jak typ wejściowy
- ROUND — typ numeryczny
Czym jest operator ANY? Opisz zasadę działania na przykładzie. #podstawy #teoria
Operator ANY służy do sprawdzania, czy przeszukiwany podzbiór danych (podzapytanie) zawiera przynajmniej jedną wartość spełniającą użyty operator.
Można go używać w sekcji WHERE i/lub w sekcji HAVING.
Składnia:
SELECT column_name
, ...
FROM table_name
WHERE expression / column operator ANY (subquery)
GROUP BY column_name, ...
HAVING expression operator ANY (subquery)
operator - jest jednym z dostępnych operatorów logicznych =, <>, !=, >, >=, < lub <=CREATE TABLE diet_menu (
diet_name text,
diet_ingredients text[]
);
INSERT INTO diet_menu VALUES ('diet1', '{apple, orange, banana}');
INSERT INTO diet_menu VALUES ('diet2', '{apple, banana}');
SELECT *
FROM diet_menu
WHERE 'orange' = ANY (SELECT UNNEST(diet_ingredients));Zasadniczo działania operatorów są takie same. Pierwszy standard SQL wszedł w życie w 1986 r., a sam SQL pochodzi z lat 1970+, stąd 2 operatory, być może jakaś wsteczna kompatybilność?
Czym jest operator ALL? Opisz zasadę działania na przykładzie. #podstawy #teoria
Operator ALL służy do sprawdzania, czy wszystkie wiersze przeszukanego podzbioru danych (podzapytania) spełniają użyty operator. Możesz go użyć w sekcji WHERE i/lub w sekcji HAVING.
Składnia:
SELECT column_name
, ...
FROM table_name
WHERE expression / column operator ALL (subquery)
GROUP BY column_name, ...
HAVING expression operator ALL (subquery)
operator - jest jednym z dostępnych operatorów logicznych =, <>, !=, >, >=, < lub <=CREATE TABLE diet_menu (
diet_name text,
diet_ingredients text[]
);
INSERT INTO diet_menu VALUES ('diet1', '{apple, orange, banana}');
INSERT INTO diet_menu VALUES ('diet2', '{apple, banana}');
SELECT *
FROM diet_menu
WHERE 'watermelon' <> ALL (SELECT UNNEST(diet_ingredients));W zasadzie działania operatorów są takie same. Pierwszy standard SQL wszedł w życie w 1986 r., a sam SQL pochodzi z lat 1970+, stąd 2 operatory, być może jakaś wsteczna kompatybilność?
Czym jest operator EXISTS? Opisz zasadę działania na przykładzie. Czy składnie EXISTS i =ANY są równoważne? #podstawy #teoria
Operator EXISTS służy do wyszukiwania wierszy, które spełniają warunek użyty w podzapytaniu. Opis enigmatyczny, ale sprowadza się do faktu, że wynikiem będą rekordy, które istnieją w podzapytaniu użytym do zbudowania EXIST. Operator EXISTS zwraca TRUE, gdy podzapytanie zwróci 1 lub więcej rekordów.
Składnia:
SELECT column_name
, ...
FROM table_name
WHERE EXISTS (SELECT column_name
FROM table_name WHERE conditions);JOIN, zgodnie z definicją, służy do łączenia tabel i wyświetlania kolumn z różnych obiektów (tabel). EXISTS jest zaprojektowane do „filtrowania” końcowego wyniku na podstawie pewnego podzapytania.
Przykład: Wyświetl wszystkie produkty (tabela PRODUCTS), które brały udział w transakcji sprzedaży (tabela SALES).
SELECT p.*
FROM products p
WHERE EXISTS (SELECT 1
FROM sales s
WHERE s.product_id = p.product_id);Załóżmy, że chcemy wyświetlić tylko produkty, dla których istnieje transakcja sprzedaży. Możemy to zrobić z EXIST, ale także z ANY.
--EXISTS
SELECT p.*
FROM products p
WHERE EXISTS (SELECT 1
FROM sales s
WHERE s.product_id = p.product_id);
-- ANY
SELECT p.*
FROM products p
WHERE p.product_id = ANY (SELECT s.product_id FROM sales s);Plan zapytania jest identyczny w obu przypadkach. Jeśli warunek logiczny jest taki sam, ANY / SOME i EXISTS są zamienne.
Hash Join (cost=201.25..226.00 rows=100 width=41) (actual time=4.312..4.597 rows=99 loops=1)
Hash Cond: (p.product_id = s.product_id)
-> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=41) (actual time=0.013..0.138 rows=1000 loops=1)
-> Hash (cost=200.00..200.00 rows=100 width=4) (actual time=4.278..4.278 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 12kB
-> HashAggregate (cost=199.00..200.00 rows=100 width=4) (actual time=4.231..4.240 rows=100 loops=1)
Group Key: s.product_id
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=4) (actual time=0.012..2.071 rows=10000 loops=1)
Planning time: 0.431 ms
Execution time: 4.677 msJak ograniczyć liczbę wierszy wyników, na przykład do 10 elementów. Podaj przykłady oparte na systemach baz danych, które znasz, a także składnię SQL zgodną ze standardem ISO. #podstawy #teoria
Prawdopodobnie znasz składnię z relacyjnej bazy danych, z którą pracujesz na co dzień:
- LIMIT (w tym MySQL, PostgreSQL, SQLite, H2)
- TOP (w tym MS SQL Server)
- ROWNUM (Oracle) — pseudokolumna w bazie danych Oracle, tworzona podczas generowania wyników, określająca kolejność pobranych wierszy
SELECT * FROM tab LIMIT 10;
SELECT * FROM tab WHERE ROWNUM <= 10;
SELECT TOP 10 * FROM tab;W pewnym sensie zostali zmuszeni do tego. Ta funkcjonalność została wprowadzona do standardu po raz pierwszy w wersji SQL:2008.
FETCH FIRST n ROWS ONLY pozwala pobrać tylko n (gdzie n jest liczbą lub wynikiem operacji, np. (2+2)) wierszy z całego zestawu wyników.
Przykłady:
SELECT * FROM tab FETCH FIRST 10 ROWS ONLY;Jaki jest odpowiednik instrukcji warunkowej IF w SQL? Podaj przykład i wyjaśnij zasadę działania. Rozwiązanie powinno opierać się na standardzie, a nie na implementacji dla danej bazy danych. #podstawy #teoria
Instrukcja warunkowa (IF) to popularna struktura w językach programowania, która umożliwia sprawdzenie warunku i wykonanie odpowiedniej akcji w zależności od tego, czy warunek jest spełniony, czy nie.
Składnia (podstawowa - w językach programowania - jako pseudokod)
IF < WARUNEK LOGICZNY >
THEN < DZIAŁANIE, KTÓRE MA ZOSTAĆ WYKONANE, GDY WARUNEK JEST USTAWIONY >
ELSE < DZIAŁANIE, KTÓRE MA ZOSTAĆ WYKONANE, GDY WARUNEK NIE JEST SPEŁNIONY >
ENDKonstrukcja taka jak powyżej nie istnieje w standardowym SQL. Istnieje jednak w proceduralnym SQL, tj. w procedurach składowanych i funkcjach wykonywanych w bazie danych.
IF istnieje w SQL i jest ukryte pod operatorem CASE
CASE
WHEN condition1 THEN action1
WHEN condition2 THEN action2
...
ELSE action_if_others_not_met
END
<b>warunek</b> - dowolna operacja, której wynikiem jest wartość logiczna PRAWDA / FAŁSZ (operator logiczny >, <, =, <> itd.; wynik podzapytania PRAWDA / FAŁSZ itd.)
<b>akcja</b> - akcja, która ma zostać wykonana, gdy spełniony jest warunek, np. wyświetlenie kolumny, dodanie czegoś do wartości itd.Jeśli ELSE nie zostało zadeklarowane, zostanie zwrócona niezdefiniowana wartość - NULL.
Operatora CASE można używać w samej składni SELECT, w WHERE, w ORDER BY, GROUP BY itd. Jednak taki operator zawsze tworzy dodatkowy narzut w momencie wykonania (na wykonanie instrukcji check + wykonanie akcji), co wpłynie na wydajność. W niektórych przypadkach warto rozważyć wcześniejsze wyliczenie kolumn za pomocą operatora CASE (jako element w procesie przed użyciem), dodanie odpowiedniego indeksowania, a następnie użycie obliczonej kolumny w SELECT.
Uwaga: W niektórych bazach danych istnieje IF, np. MySQL, lub jako IIF - Firebird / SQL Server. Nie jest to jednak standard SQL, ale nakładka na konkretną bazę danych.
Do czego służy składnia ORDER BY? Jakie dodatkowe opcje wykonania może zawierać (obsługa NULL/kierunku)? #podstawy #teoria
Operacja ORDER BY służy do sortowania wynikowych danych.
Czy wyniki mają jakiekolwiek sortowanie bez ORDER BY.
NIE. Jeśli klauzula ORDER BY nie jest podana, wyniki zapytania zostaną zwrócone w niezdefiniowanej formie. Może się zdarzyć, że pojawią się w tej samej kolejności, w jakiej zostały dodane do tabeli źródłowej, ale zachowaj ostrożność i nie traktuj tego jako pewnika.
Jeśli chcesz uzyskać wiersze w żądanej kolejności, użyj ORDER BY.
Składnia
SELECT …
FROM …
ORDER BY < COLUMN/FUNCTION_NAME > < DESC | AS C> < NULLS FIRST | NULLS LAST >- COLUMN/FUNCTION_NAME — nazwa/nazwy kolumn lub funkcji, według których ma zostać wykonane sortowanie
- DESC — sortowanie w kolejności malejącej
- ASC — sortowanie w kolejności rosnącej
- NULLS FIRST — wyświetlanie niezdefiniowanych wartości na początku zestawu wyników
- NULLS LAST — wyświetlanie niezdefiniowanych wartości na końcu zestawu wyników
Elementy używane w składni ORDER BY nie muszą znajdować się w części SELECT.
ORDER BY jest jednym z ostatnich logicznych elementów, które zostaną wykonane. Dlatego podczas sortowania możemy używać aliasów - zamiast rzeczywistych nazw kolumn lub kolejności pól zamiast ich nazw (np. ORDER BY 1, 2, 3, gdzie 1, 2, 3 to kolejne kolumny po składni SELECT)
Co to jest JOIN w języku zapytań baz danych SQL? Jakie znasz typy połączeń? #podstawy #teoria #join
JOIN to połączenie tabel (lub tabela) oparte na pewnym warunku (takie same kolumny, operatory logiczne >, < itd.).
W najprostszym przypadku używamy połączeń, aby mapować relacje między tabelami, gdy chcemy uzyskać określony wynik.
Typy połączeń:
- (INNER) JOIN
- LEFT (OUTER) JOIN
- RIGHT (OUTER) JOIN
- FULL (OUTER) JOIN
Co to jest łączenie zestawów za pomocą operacji UNION i UNION ALL? Jaka jest różnica między tymi operacjami (UNION vs UNION ALL)? #podstawy #teoria #union #unionall
UNION - to operacja łączenia zestawów danych. Możesz jej użyć do połączenia rekordów z różnych tabel w jeden zestaw rekordów.
Do czego? Zwykle, gdy musisz utworzyć listę wartości z różnych zestawów (tabel).
Ograniczenia
- liczba kolumn w obu zapytaniach musi być identyczna
- typy danych muszą być zgodne w odpowiadających sobie kolumnach - (w powyższym przykładzie car_manufacturer nie może być wartością liczbową i wartością tekstową)
- aby uzyskać posortowane wyniki, użyj ORDER BY - możesz jej użyć tylko w ostatnim SELECT. ORDER BY będzie działać na całym zestawie wyników. Jeśli chcesz uzyskać posortowane wyniki tylko z pierwszego zapytania, użyj podzapytania dla 1 SELECT
- UNION - połączy wyniki, usuwając jednocześnie zduplikowane wiersze (takie jak DISTINCT)
- UNION ALL - połączy wyniki bez usuwania zduplikowanych wierszy
Uwaga: W niektórych bazach danych UNION, oprócz usuwania duplikatów, sortuje również wynikowy zestaw danych (np. SQL Server).
Jaka jest różnica między INNER JOIN i NATURAL JOIN? #podstawy #teoria #join
INNER JOIN to typ połączenia, w którym z dwóch zestawów (tabel lub podzapytań) bierzemy wartości (wiersze), dla których spełniony jest zdefiniowany klucz połączenia. Oznacza to, że wartości w kolumnach z zestawów użytych w połączeniu mają takie same wartości (przy użyciu kolumn „=” w JOIN).
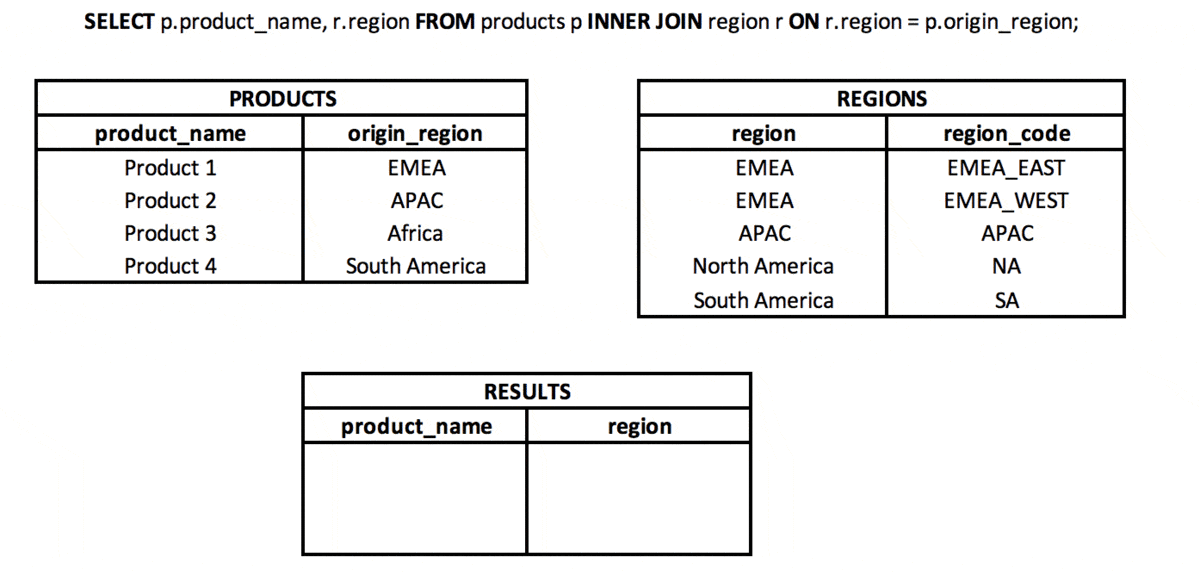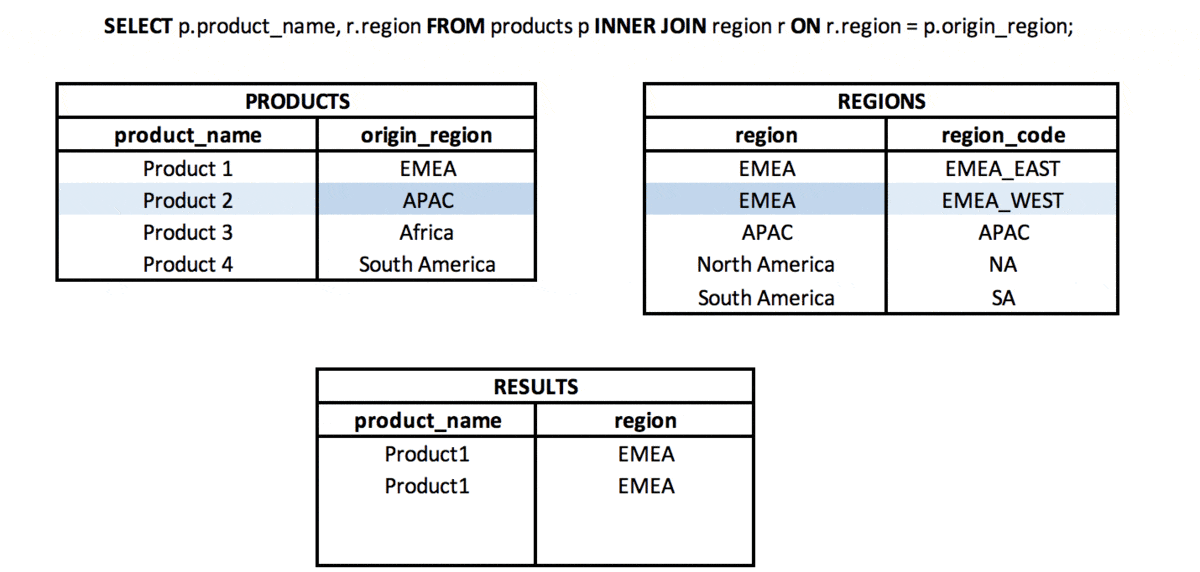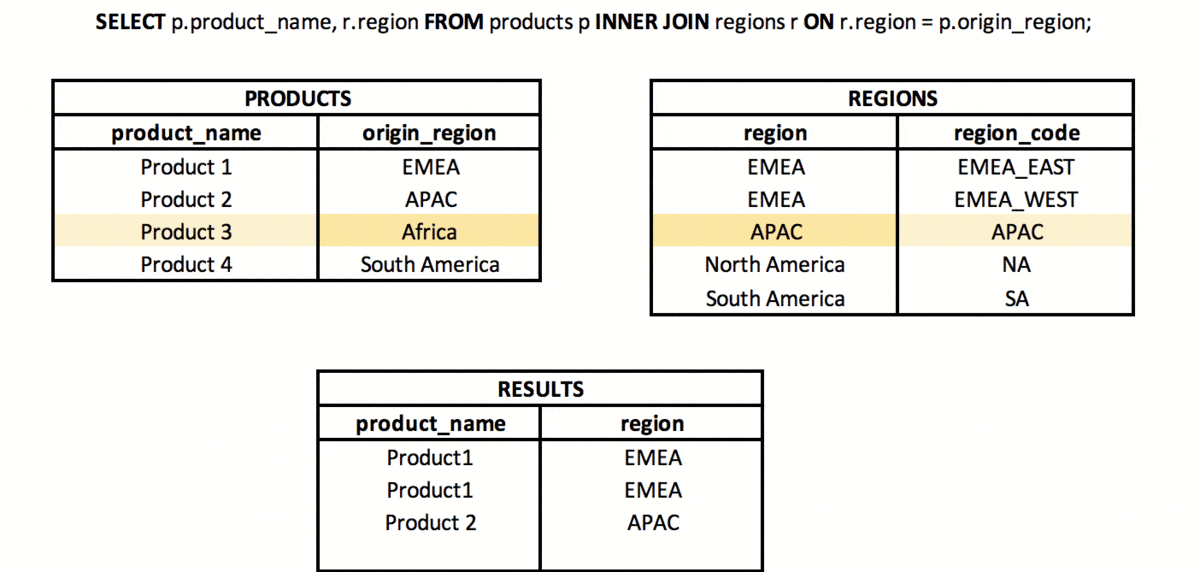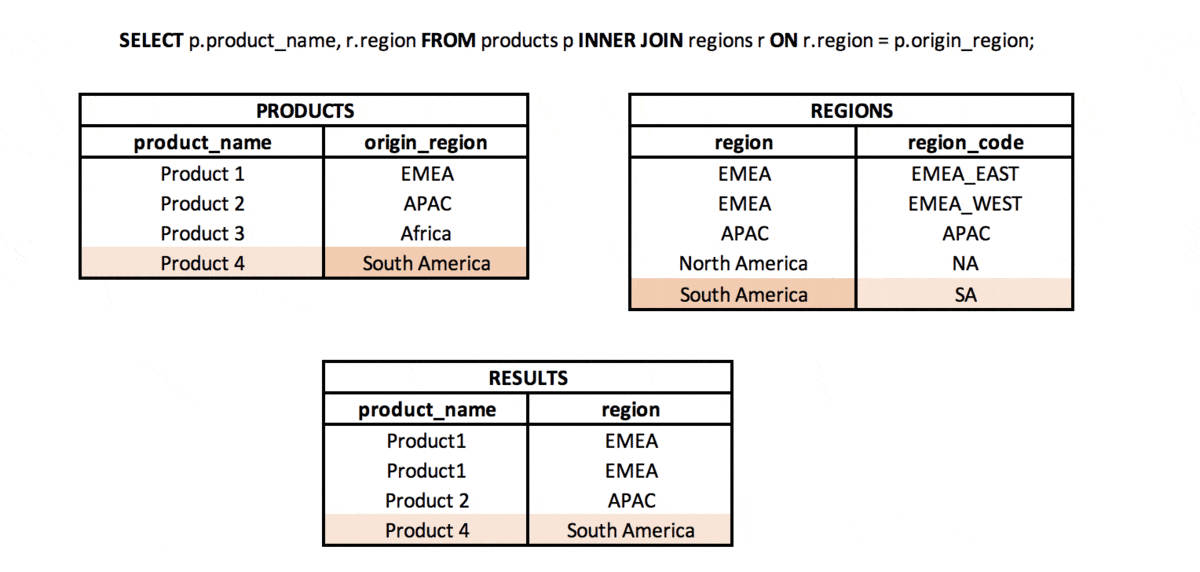
NATURAL JOIN to rodzaj połączenia, w którym bierzemy tylko wspólną część dwóch zestawów (tabel lub podzapytań), ale tylko wtedy, gdy w obu zestawach znajduje się kolumna o tej samej nazwie (lub więcej kolumn o tej samej nazwie).
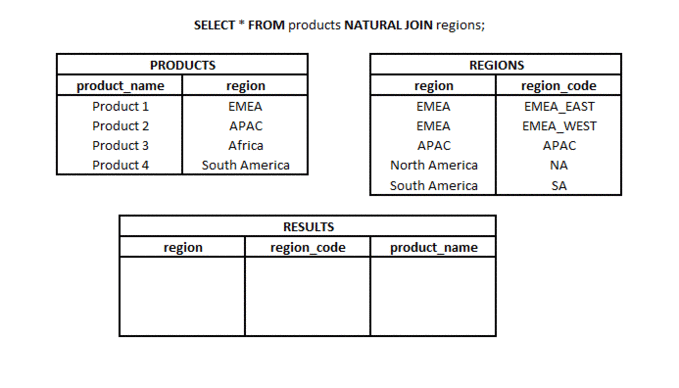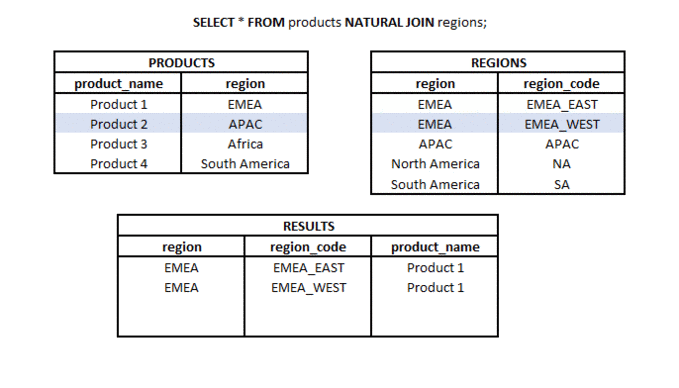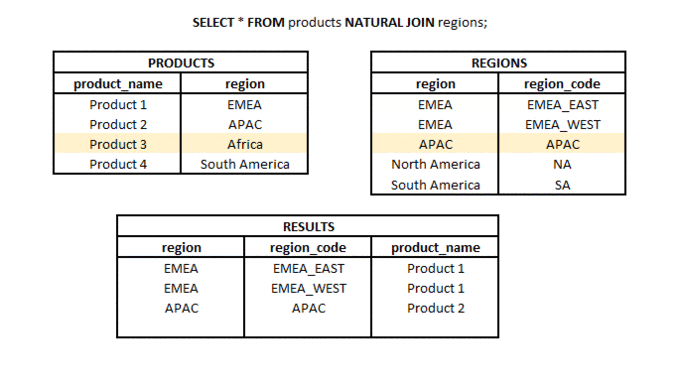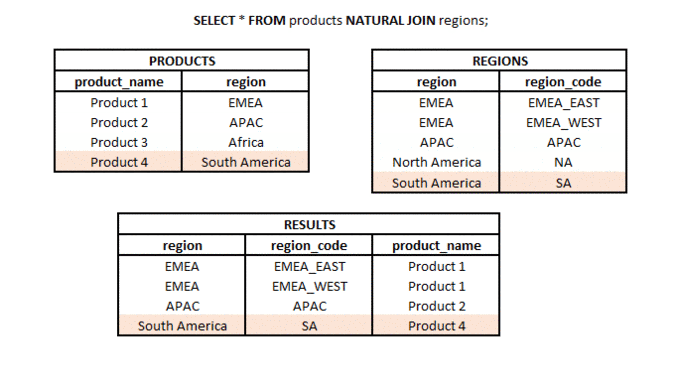
Jaka jest różnica między LEFT JOIN i RIGHT JOIN? #podstawy #teoria #join
RIGHT OUTER JOIN to typ łączenia, w którym z dwóch zestawów (tabel lub podzapytań) bierzemy wszystkie elementy z drugiego zestawu i pasujące elementy (zgodnie z użytym kluczem łączenia) z pierwszego zestawu. Stąd nazwa RIGHT (odnosząca się do kierunku łączenia) i OUTER odnosząca się do typu łączenia zewnętrznego (a nie tylko części wspólnej).
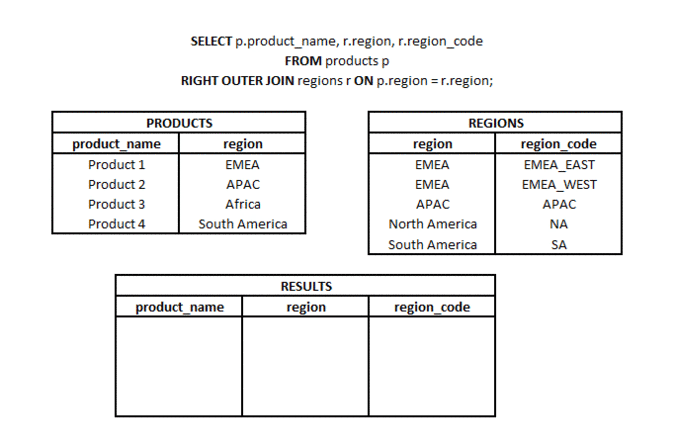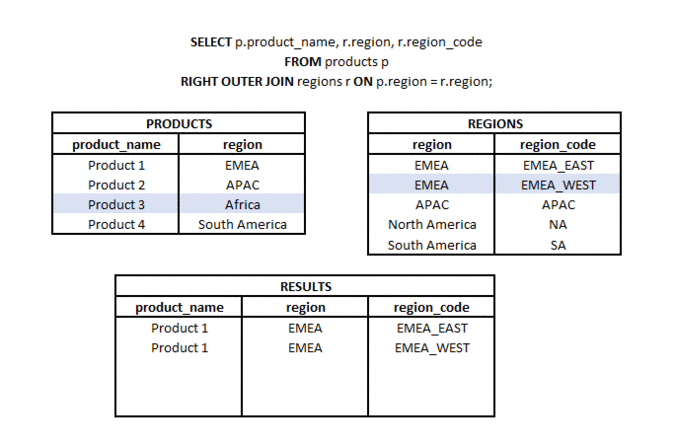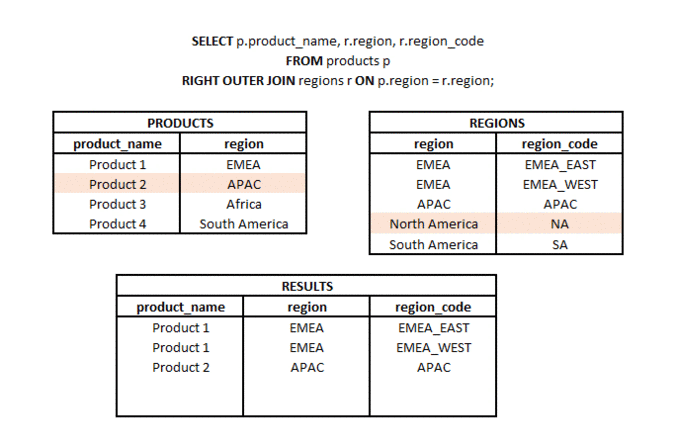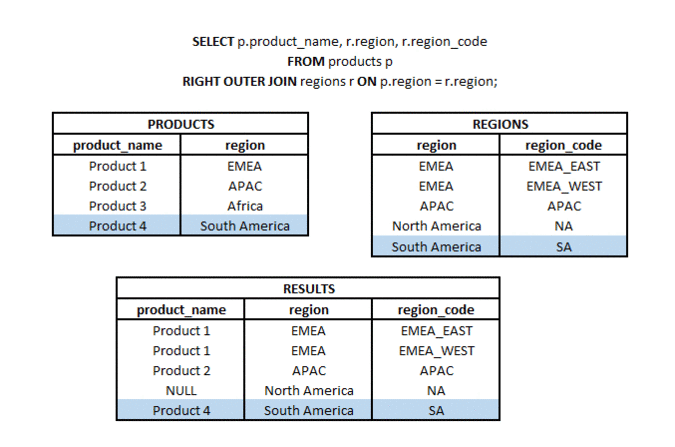
LEFT OUTER JOIN to typ połączenia, w którym z dwóch zestawów (tabel lub podzapytań) bierzemy wszystkie elementy z jednego zestawu i pasujące elementy (zgodnie z użytymi kluczami połączenia) z drugiego zestawu. Stąd nazwa LEFT (odnosząca się do kierunku połączenia) i OUTER odnosząca się do typu połączenia zewnętrznego (a nie tylko do części wspólnej).
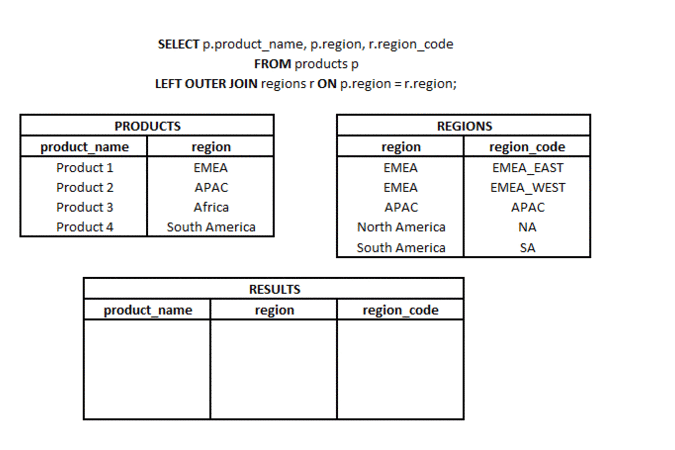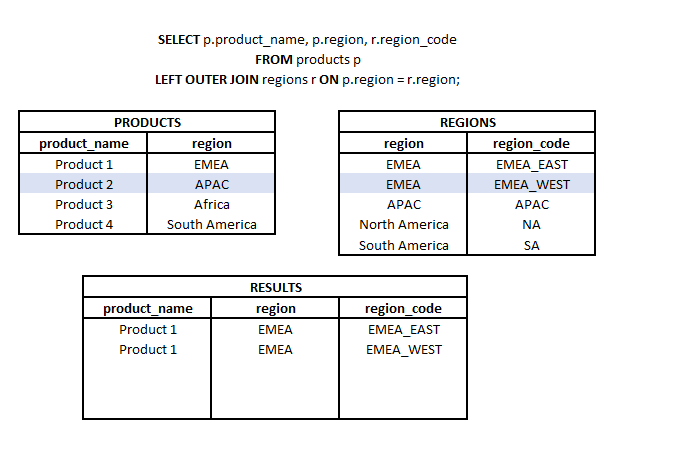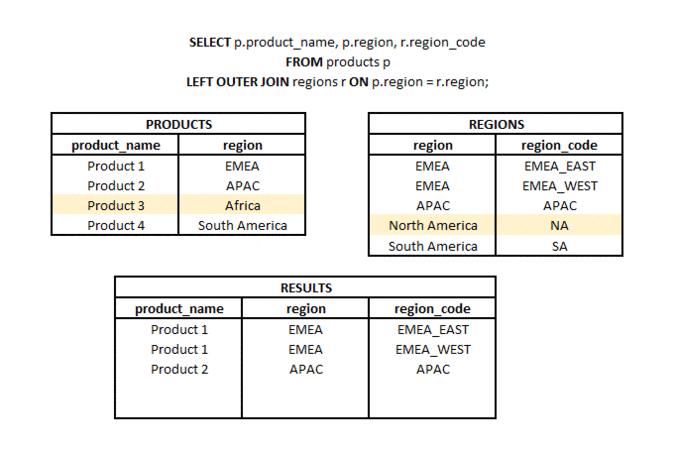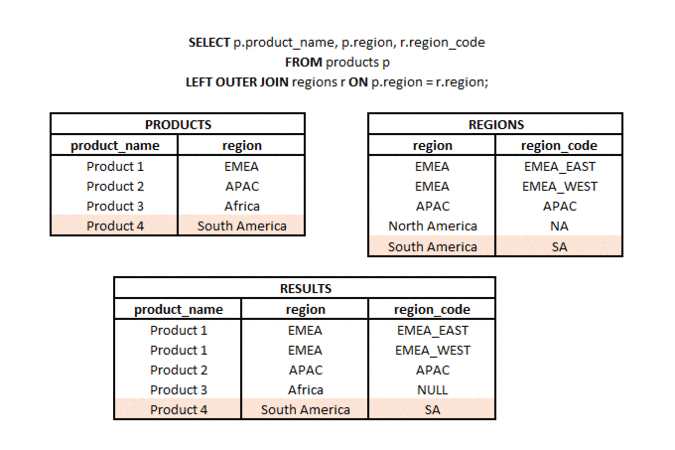
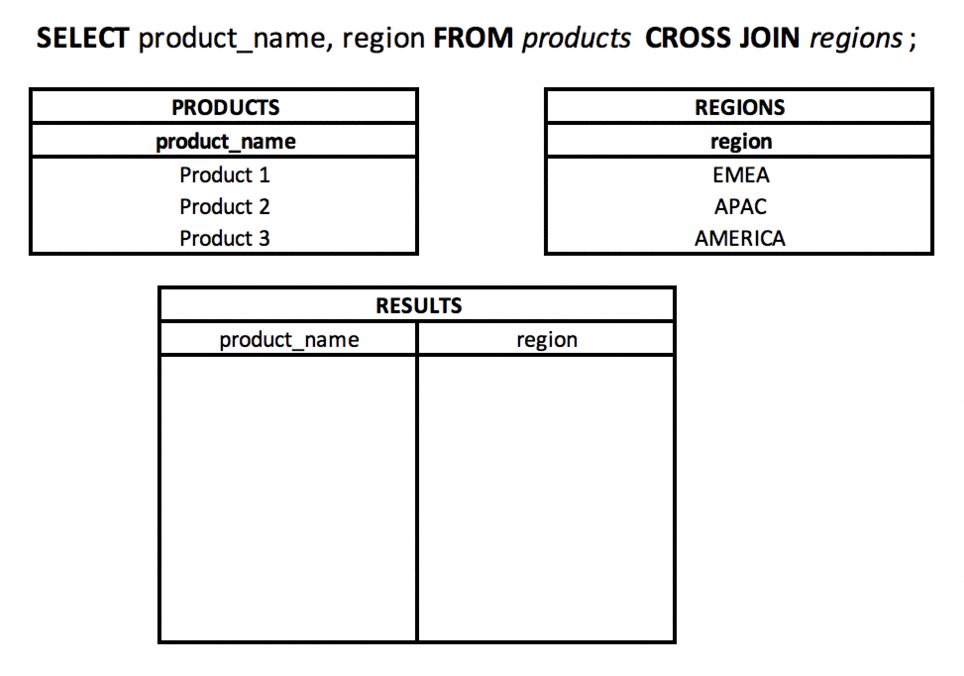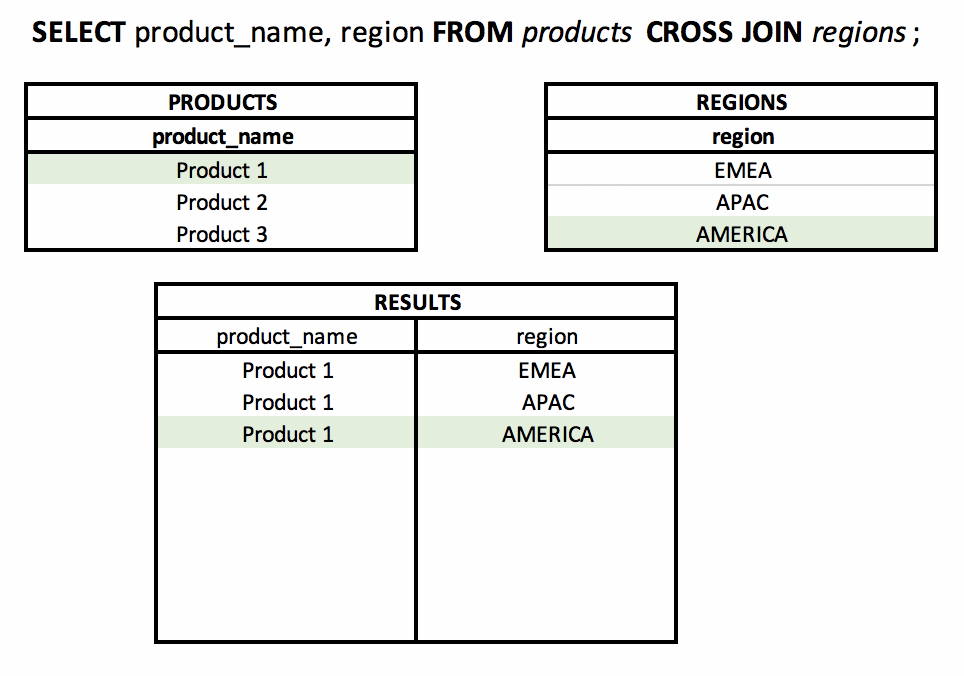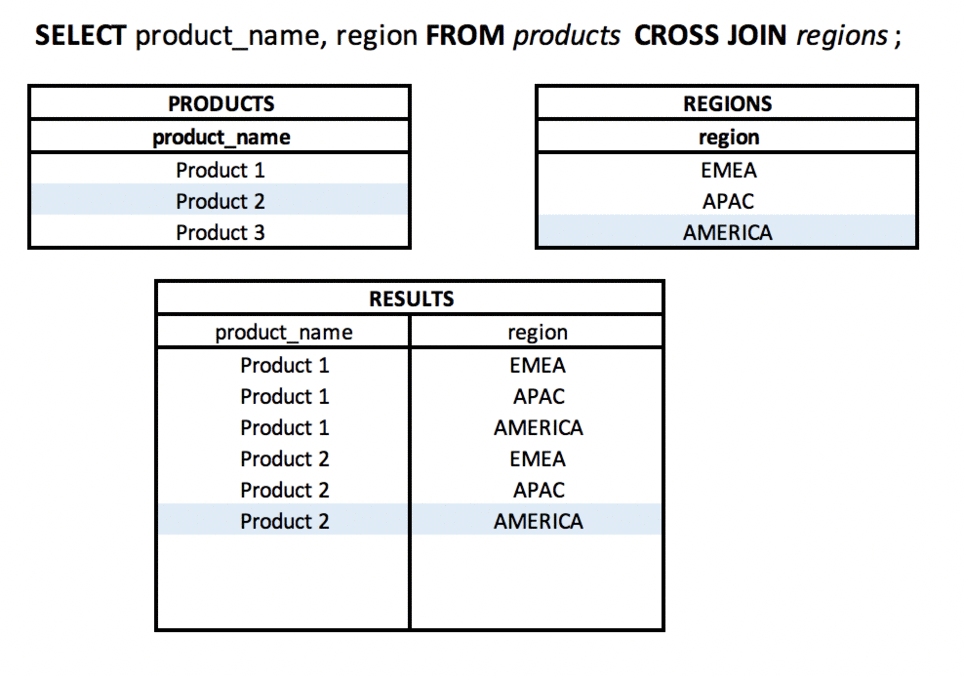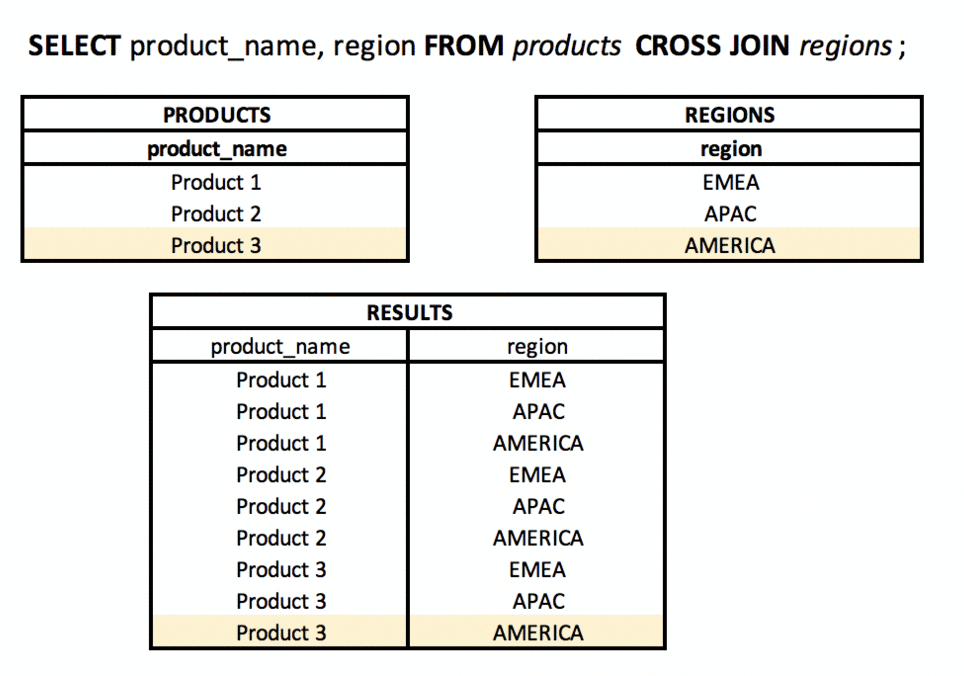
Co to jest CROSS JOIN? #podstawy #teoria #join
Używając CROSS JOIN, wynikiem będzie iloczyn kartezjański zbiorów (tabel). Każdy wiersz z tabeli A będzie „połączony” z każdym wierszem z tabeli B.
Będzie dobrze działać w sytuacjach - świadomego łączenia wszystkich wierszy ze sobą, np. wyświetlania każdego produktu w każdym regionie.
Co oznaczają EQUI / NON-EQUI i SELF JOIN? #podstawy #teoria #join
EQUI JOIN - dowolny typ połączenia, w którym używamy znaku = w kluczu połączenia.
NON-EQUI JOIN - dowolny typ połączenia, w którym nie używamy znaku = w kluczu połączenia (ale np. <. >, >=, =<, !=).
SELF JOIN - typ połączenia, w którym łączymy ten sam zestaw danych/tabele.
Jakie wewnętrzne algorytmy połączeń znasz podczas wykonywania zapytania SQL. Patrząc z perspektywy planu wykonania zapytania? #podstawy #teoria #połączenie
Wewnętrzne lub czasami nazywane fizycznymi typami połączeń, lub bardziej ogólnie algorytmami połączeń. Są to połączenia, których silnik bazy danych używa do faktycznego łączenia danych (oprócz tego, czego użytkownik użył w zapytaniu LEFT/INNER JOIN).
Trzy podstawowe typy:
- NESTED LOOP
- MERGE JOIN
- HASH JOIN
Jaki jest typ łączenia danych NESTED LOOP? #podstawy #teoria #dołącz
Biorąc pod uwagę dwa zbiory N i M do połączenia, w najprostszym (najgorszym) scenariuszu każdy rekord w zbiorze N musi zostać sprawdzony względem rekordów w zbiorze M.
Stąd nazwa "pętla zagnieżdżona (NESTED LOOP)", przechodzimy przez elementy zbioru M, iterując elementy zbioru N.
W zależności od sytuacji złożoność tego algorytmu może wynosić:
- O(N*M), gdy nie ma indeksu na kluczu dołączenia zbioru
- O(M*logN), gdy mamy indeks B-Tree na jednym z kluczy dołączenia
- O(M), gdy mamy indeks haszujący na jednym z kluczy dołączenia.
Przykład oparty na tabelach PRODUKTY i SPRZEDAŻ:
CREATE INDEX product_id_sales_idx ON sales (product_id);
CREATE INDEX product_name_products_idx ON products (product_name);
EXPLAIN ANALYZE
SELECT *
FROM products p
JOIN sales s ON s.product_id = p.product_id
AND p.product_name = 'Product 1';
QUERY PLAN
Nested Loop (cost=4.77..68.41 rows=28 width=1148) (actual time=0.369..2.142 rows=1236 loops=1)
-> Index Scan using product_name_products_idx on products p (cost=0.27..8.29 rows=1 width=1068) (actual time=0.029..0.098 rows=101 loops=1)
Index Cond: ((product_name)::text = 'Product 1'::text)
-> Bitmap Heap Scan on sales s (cost=4.50..59.85 rows=28 width=80) (actual time=0.005..0.016 rows=12 loops=101)
Recheck Cond: (product_id = p.product_id)
Heap Blocks: exact=685
-> Bitmap Index Scan on product_id_sales_idx (cost=0.00..4.49 rows=28 width=0) (actual time=0.003..0.003 rows=12 loops=101)
Index Cond: (product_id = p.product_id)
Planning time: 0.498 ms
Execution time: 2.281 msJaki jest typ łączenia danych MERGE JOIN? #podstawy #teoria #join
Jeśli chcesz połączyć dwa zbiory N i M. Algorytm MERGE JOIN zostanie użyty, gdy zbiory użyte w połączeniu zostaną posortowane według klucza łączenia, a operator równości zostanie użyty w kluczu łączenia.
Co to oznacza w praktyce? Gdy mamy dwa posortowane zbiory, sprawdzanie równości jest bardzo uproszczone.
Patrząc na zbiór N i mając wartość 1, szukamy tej wartości w posortowanym zbiorze M. Bierzemy pierwszy element, czy jest równy 1, nie, czy jest większy, tak - nie sprawdzamy kolejnych elementów. Następnie bierzemy kolejny rekord ze zbioru N. Ta operacja jest powtarzana, aż wszystkie elementy z jednego ze zbiorów zostaną sprawdzone (Dlaczego z jednego? Ponieważ zbiory są posortowane i przeszukaliśmy wszystko ze zbioru, np. N jest zbiorem M, nic nowego nas już nie zaskoczy, ponieważ niezaznaczone wartości i tak nie spełnią warunków łączenia).
Złożoność tego algorytmu wynosi O(N+M).
Świetne do łączenia w „dużych” tabelach, gdy oba zbiory są posortowane według klucza łączenia, a warunek łączenia używa operatora równości „=”.
Przykład oparty na tabelach PRODUKTY i SPRZEDAŻ:
EXPLAIN ANALYZE
SELECT *
FROM (SELECT *
FROM products
ORDER BY product_id) p
JOIN (SELECT *
FROM sales
ORDER BY product_id) s ON s.product_id = p.product_id;
QUERY PLAN
Merge Join (cost=909.82..1184.70 rows=10000 width=97) (actual time=3.885..8.134 rows=9893 loops=1)
Merge Cond: (products.product_id = sales.product_id)
-> Sort (cost=69.83..72.33 rows=1000 width=41) (actual time=0.249..0.260 rows=100 loops=1)
Sort Key: products.product_id
Sort Method: quicksort Memory: 103kB
-> Seq Scan on products (cost=0.00..20.00 rows=1000 width=41) (actual time=0.014..0.110 rows=1000 loops=1)
-> Materialize (cost=838.39..988.39 rows=10000 width=56) (actual time=3.556..6.009 rows=10000 loops=1)
-> Sort (cost=838.39..863.39 rows=10000 width=56) (actual time=3.550..4.883 rows=10000 loops=1)
Sort Key: sales.product_id
Sort Method: quicksort Memory: 1166kB
-> Seq Scan on sales (cost=0.00..174.00 rows=10000 width=56) (actual time=0.009..1.003 rows=10000 loops=1)
Planning time: 1.770 ms
Execution time: 8.658 msJaki jest typ łączenia danych HASH JOIN? #podstawy #teoria #łączenie
Jeśli chcesz połączyć dwa zbiory N i M, zostanie użyty algorytm HASH JOIN.
Baza danych dla mniejszego zbioru określi skróty dla kluczy łączenia i zbuduje tablicę skrótów (łącząc wyznaczony skrót z rzeczywistym rekordem tabeli N).
Następnie, w pętli, dla każdego rekordu z tabeli M, zostanie ustalony skrót dla klucza łączenia i porównany z utworzoną tablicą skrótów.
Tablica skrótów jest zwykle przechowywana w pamięci, ale gdy zbiór danych jest bardzo duży, ilość miejsca w pamięci może być niewystarczająca, więc część tablicy skrótów zostanie zrzucona na dysk i odczytana z niego (co znacznie spowolni odczyt/łączenie).
Złożoność obliczeniowa tego algorytmu, zakładając, że tablica skrótów zmieści się w pamięci i nie zostaną wykorzystane żadne dodatkowe zasoby, wynosi: O(N+M).
Przykład oparty na tabelach PRODUCTS i SALES:
EXPLAIN ANALYZE
SELECT *
FROM products p
JOIN sales s ON s.product_id = p.product_id
AND p.product_name = 'Product 1';QUERY PLAN
Hash Join (cost=23.65..244.35 rows=920 width=97) (actual time=0.231..2.355 rows=996 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=56) (actual time=0.011..0.959 rows=10000 loops=1)
-> Hash (cost=22.50..22.50 rows=92 width=41) (actual time=0.193..0.193 rows=92 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 15kB
-> Seq Scan on products p (cost=0.00..22.50 rows=92 width=41) (actual time=0.016..0.181 rows=92 loops=1)
Filter: ((product_name)::text = 'Product 1'::text)
Rows Removed by Filter: 908
Planning time: 0.404 ms
Execution time: 2.445 msCo może determinować wybór metody łączenia (NESTED LOOP, MERGE JOIN, HASH JOIN) przez optymalizator w bazie danych? #podstawy #teoria #łączenie
Z magii bazy danych, której używasz... ale poważnie, możemy uwzględnić następujące elementy:
- rozmiar zestawów danych używanych w połączeniu
- operator klucza łączenia (czy jest to operator równości "=" czy inny)
- w zależności od tego, czy na kluczach łączenia znajdują się indeksy
- czy statystyki tabel używanych w połączeniu są aktualne (obliczone)
Warto przeanalizować plan wykonania zapytania (EXPLAIN / EXPLAIN ANALYZE) i czasami zakwestionować metodę łączenia zestawów przedstawioną przez optymalizator bazy danych.
Co to jest duplikat w danych? #podstawy #teoria
Co najmniej 2 wiersze wyników, dla których wszystkie kolumny mają takie same wartości, nazywane są duplikatem w danych.
Przykład:
PRODUCT_NAME | PRODUCT_CATEGORY
Product 1 | Category 1
Product 1 | Category 1Co to jest NULL w bazach danych relacyjnych? Jakie znasz sposoby radzenia sobie z wartością NULL przy ograniczaniu danych wynikowych (WHERE)? #podstawy #teoria
NULL to rodzaj znacznika w bazach danych SQL i relacyjnych, który wskazuje, że dana wartość jest niezdefiniowana (w danych źródłowych nie ma żadnej wartości).
Uwaga: NULL nie jest 0 dla liczb ani pustym tekstem dla wartości tekstowych.
Sposoby radzenia sobie z wartością NULL obejmują:
- porównania warunkowe IS NULL / IS NOT NULL
- COALESCE() — funkcja, która w przypadku wystąpienia wartości NULL zastąpi ją podaną wartością, np. COALESCE(product_name, 'unknown_product');
- CASE — składnia umożliwiająca zbudowanie warunkowego podejścia do wartości kolumny/funkcji CASE WHEN product_name IS NULL THEN 'unknown_product' ELSE product_name END
Istnieją również inne alternatywy, np. NULLIF(), IFNULL(), ISNULL(), NVL() — których zadaniem jest wykonywanie tej samej lub podobnej funkcji, tj. radzenie sobie z niezdefiniowaną wartością.
Co można wykorzystać, gdy nie chcemy, aby wartości w kolumnie były niezdefiniowane w tabeli, a jednocześnie nie chcemy otrzymać błędu podczas próby WSTAWIENIA wartości NULL? #podstawy #teoria
Dodanie OGRANICZENIA (CONSTRAINT) typu NOT NULL z dodatkową wartością domyślną DEFAULT ''.
Uwaga: To nie zawsze może być pożądane rozwiązanie. Czasami wartości NULL są całkowicie OK i takie ograniczenie pozwoli nam sobie z nimi poradzić w tabeli, ale podczas budowania SELECT z połączeniami możemy nadal otrzymywać niezdefiniowane wartości.
CREATE TABLE products_constraint (
product_id SERIAL,
product_name varchar(500),
product_category varchar(250) NOT NULL DEFAULT '< unknown >',
random_desc text
);
INSERT INTO products_constraint (product_name,random_desc) VALUES ('Product New Special One', 'Special Constraint Product');
SELECT * FROM products_constraint;
product_id: 1
product_name: Product New Special One
product_category: < unknown >
random_desc: Special Constraint ProductCo to jest operator LIKE? W jakich sytuacjach go używamy i jakie są podstawowe znaki specjalne używane przez ten operator? #podstawy #teoria
Używamy operatora LIKE w sekcji WHERE zapytania, aby znaleźć/przefiltrować wiersze wyników zgodnie z wybranym wzorcem w danych tekstowych.
Wynik operatora w danym wierszu jest PRAWDA lub FAŁSZ w zależności od tego, czy dany wzorzec pasuje do wyniku (PRAWDA) czy nie pasuje (FAŁSZ). W odwrotnej sytuacji, gdy chcemy znaleźć dane, które nie pasują do wzorca, użyjemy operatora NOT LIKE.
Operator LIKE może używać 2 znaków specjalnych:
- % - znak procentu oznacza wystąpienie 0,1 lub więcej znaków (dowolny) w wyszukiwanym wzorcu
- _ - podkreślenie (dolny wiersz), oznacza wystąpienie 1 znaku (dowolny)
- [] - nawiasy kwadratowe - dowolny ze znaków zawartych w nawiasach kwadratowych (SQL Server)
- ^ - „daszek” oznacza negację, np. [^cb] wszystkie znaki poza c lub b w słowie
- - - myślnik oznacza zakres znaków, np. [a - e]
Na podstawie danych sprzedaży (tabela SALES) znajdź listę unikalnych istniejących nazw produktów (tabela PRODUCTS, kolumna PRODUCT_NAME) #practice #syntax
SELECT DISTINCT
p.product_name as unq_product_name
FROM sales s
JOIN products p on p.product_id< = s.product_id;
inne rozwiązanie:
SELECT count(*) as unq_product_count
FROM (SELECT DISTINCT
p.product_name
FROM sales s
JOIN products p on p.product_id = s.product_id
) sq;Na podstawie danych sprzedaży (tabela SALES) znajdź liczbę unikalnych istniejących nazw produktów (tabela PRODUCTS, kolumna PRODUCT_NAME) #practice #syntax #antipartterns
SELECT count(distinct p.product_name) as unq_product_count
FROM sales s
JOIN products p on p.product_id = s.product_id;SELECT DISTINCT
count(p.product_name) as not_so_unq_product_count
FROM sales s
JOIN products p on p.product_id = s.product_id;Bez użycia klauzuli DISTINCT, znajdź listę unikalnych produktów (kolumna PRODUCT_NAME) na podstawie danych sprzedaży (tabela SALES) #practice #syntax
SELECT product_name as unq_product_name
FROM (SELECT p.product_name,
row_number() over (partition by p.product_name) as rn
FROM sales s
JOIN products p on p.product_id = s.product_id
) sq
WHERE rn = 1;DISTINCT vs ROW_NUMBER() OVER(), które rozwiązanie będzie szybsze na podstawie dostępnych danych? Sprawdź wyniki, korzystając z planu zapytania. #praktyka #wydajność
EXPLAIN ANALYZE
SELECT DISTINCT
p.product_name as unq_product_name
FROM sales s
JOIN products p on p.product_id = s.product_id;
/* QUERY PLAN
HashAggregate (cost=369.00..369.10 rows=10 width=10) (actual time=5.632..5.633 rows=10 loops=1)
Group Key: p.product_name
-> Hash Join (cost=32.50..344.00 rows=10000 width=10) (actual time=0.386..4.036 rows=9899 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=4) (actual time=0.012..1.236 rows=10000 loops=1)
-> Hash (cost=20.00..20.00 rows=1000 width=14) (actual time=0.348..0.348 rows=1000 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 55kB -> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=14) (actual time=0.010..0.180 rows=1000 loops=1)
Planning time: 0.298 ms
Execution time: 5.694 ms
*/
EXPLAIN ANALYZE
SELECT product_name as unq_product_name
FROM (SELECT p.product_name,
row_number() over (partition by p.product_name) as rn
FROM sales s
JOIN products p on p.product_id = s.product_id
) sq
WHERE rn = 1;
/* QUERY PLAN
Subquery Scan on sq (cost=1008.39..1308.39 rows=50 width=10) (actual time=12.051..18.867 rows=10 loops=1)
Filter: (sq.rn = 1)
Rows Removed by Filter: 9889
-> WindowAgg (cost=1008.39..1183.39 rows=10000 width=18) (actual time=12.045..17.678 rows=9899 loops=1)
-> Sort (cost=1008.39..1033.39 rows=10000 width=10) (actual time=12.039..13.206 rows=9899 loops=1)
Sort Key: p.product_name
Sort Method: quicksort Memory: 849kB
-> Hash Join (cost=32.50..344.00 rows=10000 width=10) (actual time=0.531..4.770 rows=9899 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=4) (actual time=0.009..1.103 rows=10000 loops=1)
-> Hash (cost=20.00..20.00 rows=1000 width=14) (actual time=0.493..0.493 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 55kB
-> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=14) (actual time=0.008..0.225 rows=1000 loops=1)
Planning time: 0.342 ms
Execution time: 19.018 ms
*/Na podstawie danych sprzedaży (tabela SALES) znajdź listę produktów, które nie zostały zakupione, używając składni IS NULL. #praktyka #składnia
SELECT *
FROM products p
LEFT JOIN sales s on s.product_id = p.product_id
WHERE s.id IS NULL;Na podstawie danych sprzedaży (tabela SALES) znajdź listę produktów, które nie zostały zakupione, nie używając składni IS NULL. #praktyka #składnia
SELECT *
FROM products p
WHERE product_id NOT IN (SELECT DISTINCT product_id FROM sales);SELECT p.*
FROM products p
EXCEPT
SELECT DISTINCT p.*
FROM sales s
JOIN products p ON s.product_id = p.product_id;IS NULL vs NOT IN vs EXCEPT, sprawdź na podstawie dostępnych danych, korzystając z planu zapytania, które rozwiązanie będzie szybsze. Cel we wszystkich przypadkach jest taki sam: znalezienie listy produktów (tabela PRODUCTS), które nie zostały zakupione (tabela SALES) #praktyka #wydajność
EXPLAIN ANALYZE
SELECT p.*
FROM products p
LEFT JOIN sales s ON s.product_id = p.product_id
WHERE s.id IS NULL;
/*
Hash Right Join (cost=3.25..35.00 rows=1 width=41) (actual time=0.451..0.453 rows=1 loops=1)
Hash Cond: (s.product_id = p.product_id)
Filter: (s.id IS NULL)
Rows Removed by Filter: 984
-> Seq Scan on sales s (cost=0.00..18.00 rows=1000 width=8) (actual time=0.007..0.117 rows=1000 loops=1)
-> Hash (cost=2.00..2.00 rows=100 width=41) (actual time=0.057..0.057 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 16kB
-> Seq Scan on products p (cost=0.00..2.00 rows=100 width=41) (actual time=0.014..0.021 rows=100 loops=1)
Planning time: 0.425 ms
Execution time: 0.515 ms
*/
EXPLAIN ANALYZE
SELECT *
FROM products p
WHERE product_id NOT IN (SELECT DISTINCT product_id FROM sales);
/*
Seq Scan on products p (cost=21.75..24.00 rows=50 width=41) (actual time=0.555..0.555 rows=1 loops=1)
Filter: (NOT (hashed SubPlan 1))
Rows Removed by Filter: 99
SubPlan 1
-> HashAggregate (cost=20.50..21.50 rows=100 width=4) (actual time=0.445..0.464 rows=100 loops=1)
Group Key: sales.product_id
-> Seq Scan on sales (cost=0.00..18.00 rows=1000 width=4) (actual time=0.008..0.124 rows=1000 loops=1)
Planning time: 0.142 ms
Execution time: 0.600 ms
*/
EXPLAIN ANALYZE
SELECT p.*
FROM products p
EXCEPT
SELECT DISTINCT p.*
FROM sales s
JOIN products p ON s.product_id = p.product_id;
/*
HashSetOp Except (cost=0.00..52.00 rows=100 width=1072) (actual time=1.142..1.142 rows=1 loops=1)
-> Append (cost=0.00..50.00 rows=200 width=1072) (actual time=0.012..1.034 rows=199 loops=1)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..3.00 rows=100 width=45) (actual time=0.011..0.037 rows=100 loops=1)
-> Seq Scan on products p (cost=0.00..2.00 rows=100 width=41) (actual time=0.009..0.016 rows=100 loops=1)
-> Subquery Scan on "*SELECT* 2" (cost=45.00..47.00 rows=100 width=45) (actual time=0.954..0.977 rows=99 loops=1)
-> HashAggregate (cost=45.00..46.00 rows=100 width=41) (actual time=0.953..0.967 rows=99 loops=1)
Group Key: p_1.product_id, p_1.product_name, p_1.product_category, p_1.random_desc
-> Hash Join (cost=3.25..35.00 rows=1000 width=41) (actual time=0.052..0.515 rows=984 loops=1)
Hash Cond: (s.product_id = p_1.product_id)
-> Seq Scan on sales s (cost=0.00..18.00 rows=1000 width=4) (actual time=0.006..0.108 rows=1000 loops=1)
-> Hash (cost=2.00..2.00 rows=100 width=41) (actual time=0.028..0.028 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 16kB
-> Seq Scan on products p_1 (cost=0.00..2.00 rows=100 width=41) (actual time=0.003..0.010 rows=100 loops=1)
Planning time: 0.149 ms
Execution time: 1.272 ms
*/Wyświetl listę wszystkich produktów (tabela PRODUCTS) wraz z datą ich sprzedaży (tabela SALES). Jeśli nie ma sprzedaży danego produktu, podaj datę jako 1900-01-01. #praktyka #składnia
SELECT p.*,
COALESCE(s.sales_date, '1900-01-01') as sales_date
FROM products p
LEFT JOIN sales s on s.product_id = p.product_id
ORDER BY s.sales_date NULLS FIRST; SELECT p.*,
CASE WHEN s.sales_date IS NULL THEN '1900-01-01'
ELSE s.sales_date
END as sales_date
FROM products p
LEFT JOIN sales s on s.product_id = p.product_id
ORDER BY s.sales_date NULLS FIRST;Znajdź wszystkie produkty (z tabeli PRODUCTS), których nazwa produktu (kolumna PRODUCT_NAME) kończy się na 1. #praktyka #składnia
SELECT *
FROM products
WHERE product_name LIKE '%1';Znajdź wszystkie produkty (z tabeli PRODUCTS), których opis (kolumna RANDOM_DESC) zaczyna się od a51. #praktyka #składnia
SELECT *
FROM products
WHERE random_desc LIKE 'a51%';Znajdź wszystkie produkty (z tabeli PRODUCTS), których nazwa produktu (kolumna PRODUCT_NAME) zawiera dokładnie 1 znak na końcu (dla przejrzystości nazwa produktu składa się z części „Produkt” i cyfry lub liczby oznaczającej numer produktu, np. Produkt 1). #praktyka #składnia
SELECT *
FROM products
WHERE product_name LIKE 'Product _';Znajdź wszystkie identyfikatory produktów (kolumna PRODUCT_ID) i nazwy produktów (kolumna PRODUCT_NAME), zarówno dla istniejących, jak i nieistniejących produktów w tabeli słownika (PRODUCTS). W przypadku nieistniejących produktów ustaw wartość nazwy produktu na 'unknown'. #praktyka #składnia #join
SELECT COALESCE(p.product_id, s.product_id) as product_id,
COALESCE(p.product_name,'unknown') as product_name
FROM sales s
LEFT JOIN products p on p.product_id = s.product_id;Na podstawie danych sprzedaży (tabela SALES) znajdź wszystkie unikalne identyfikatory produktów (kolumna PRODUCT_ID) i nazwy produktów (kolumna PRODUCT_NAME) wyłącznie dla produktów znajdujących się w tabeli słownika PRODUCTS. #praktyka #składnia #join
SELECT DISTINCT s.product_id, p.product_name
FROM sales s
JOIN products p on p.product_id = s.product_id;Pokaż dowolne 10 wierszy na podstawie danych sprzedaży (tabela SALES), dodając informacje o opisie produktu dla każdego wiersza na podstawie 1 produktu wybranego z tabeli słownika PRODUCTS. Dodatkowo wyświetl opis faktycznego produktu, który został sprzedany. Nazwij kolumnę opisem wybranego produktu, selected_product_description. Nazwij kolumnę faktycznym opisem sprzedanego produktu, valid_product_description. #praktyka #składnia #join
WITH selected_product AS (
SELECT random_desc as selected_product_description
FROM products
WHERE product_name = 'Product 1'
LIMIT 1
) SELECT s.*,
sp.selected_product_description,
p.random_desc as valid_product_description
FROM sales s
JOIN selected_product sp on 1=1
LEFT JOIN products p on p.product_id = s.product_id
LIMIT 10;Na podstawie danych sprzedaży (tabela SALES) wyświetl listę nazw produktów (kolumna PRODUCT_NAME) i liczbę ich sprzedaży. W przypadku produktów, które nie są dostępne w danych sprzedaży, wyświetl nazwę produktu i wartość 0. Posortuj wyniki alfabetycznie według nazwy produktu. #praktyka #składnia #join
SELECT p.product_name,
count(s.id) as amount_sold
FROM sales s
RIGHT JOIN products p on p.product_id = s.product_id
GROUP BY p.product_name
ORDER BY p.product_name;Wyświetl dane sprzedażowe (tabla SALES), datę sprzedaży (kolumna SALES_DATE), wartość sprzedaży (kolumna SALES_AMOUNT) i informacje o produkcie, nazwę produktu (kolumna PRODUCT_NAME), kategorię produktu (kolumna PRODUCT_CATEGORY), opis produktu (kolumna RANDOM_DESC) dla wszystkich dostępnych danych. Posortuj wyniki malejąco według wartości sprzedaży. #praktyka #składnia #join
SELECT s.sales_date
, s.sales_amount
, p.product_name
, p.product_category
FROM sales s
FULL JOIN products p on p.product_id = s.product_id
ORDER BY p.product_name;Wyświetl wszystkie produkty (tabela PRODUCTS) wraz z informacjami o dacie sprzedaży. Posortuj uzyskane dane według daty sprzedaży (kolumna SALES_DATE) od ostatniej (najbliższej dzisiejszej) do pierwszej sprzedaży. Wartości nieokreślone dla daty sprzedaży (kolumna SALES_DATE) powinny zostać uwzględnione na końcu zestawu wyników. #praktyka #składnia #join
SELECT s.sales_date
, p.*
FROM products p
LEFT JOIN sales s ON s.product_id = p.product_id
ORDER BY s.sales_date DESC NULLS LAST;Na podstawie danych sprzedaży (tabela SALES) wyświetl wszystkie unikalne nazwy produktów (kolumna PRODUCT_NAME), które były zaangażowane w transakcję sprzedaży przynajmniej raz. Otrzymane dane zostaną posortowane alfabetycznie według nazwy produktu (kolumna PRODUCT_NAME). #praktyka #składnia #join
SELECT DISTINCT
p.product_name
FROM sales s
JOIN products p ON s.product_id = p.product_id
ORDER BY p.product_name;Wyświetl wszystkie dane sprzedażowe (tabela SALES). Posortuj uzyskane dane według miesiąca sprzedaży na podstawie daty sprzedaży (kolumna SALES_DATE). Aby sprawdzić, czy wyniki są poprawne, dodaj kolumnę month_of_sales do zestawu wyników, która będzie miesiącem sprzedaży na podstawie daty sprzedaży. #praktyka #składnia
SELECT s.*,
EXTRACT(MONTH FROM s.sales_date) as month_of_sales
FROM sales s
ORDER BY month_of_sales;Na podstawie danych sprzedażowych (tabela SALES) oblicz całkowitą sumę sprzedaży (kolumna SALES_AMOUNT) dla produktu o nazwie (kolumna PRODUCT_NAME) „Product 1”. Zaokrągl wynik do jednego miejsca po przecinku. #praktyka #składnia #join
SELECT ROUND(SUM(s.sales_amount),1) as sum_of_sales
FROM sales s
JOIN products p ON p.product_id = s.product_id
AND p.product_name = 'Product 1';Na podstawie danych sprzedażowych (tabela SALES) oblicz całkowitą liczbę sprzedanych artykułów (kolumna SALES_QTY) dla produktu o nazwie (kolumna PRODUCT_NAME) „Product 2”. W wyniku przedstaw wartość zaokrągloną do najmniejszej liczby całkowitej większej lub równej wartości wyjściowej - total_sales_qty_plus, i wartość zaokrągloną do największej liczby całkowitej mniejszej lub równej wartości wyjściowej - total_sales_qty_minus. #praktyka #składnia #join #rounding
SELECT CEIL(SUM(s.sales_qty)) as total_sales_qty_plus,
FLOOR(SUM(s.sales_qty)) as total_sales_qty_minus
FROM sales s
JOIN products p ON p.product_id = s.product_id
AND p.product_name = 'Product 2';Na podstawie danych sprzedażowych (tabela SALES) pobierz 10 wierszy, dla których wartość sprzedaży (kolumny SALES_AMOUNT) jest większa niż 5. #praktyka #składnia
SELECT s.*
FROM sales s
WHERE s.sales_amount > 5
FETCH FIRST 10 ROWS ONLY;Wyświetl wszystkie dane sprzedażowe (tabela SALES), dodając kolumnę sales_meets_expectations do wyniku, który w zależności od wartości sprzedaży (kolumna SALES_AMOUNT) będzie miał wartość 'Y' - dla wartości sprzedaży większych niż 5, 'N' - dla wartości sprzedaży mniejszych lub równych 5 i 'N/A' w pozostałych przypadkach. #praktyka #składnia
SELECT s.*,
CASE
WHEN s.sales_amount > 5 THEN TRUE
WHEN s.sales_amount <= 5 THEN FALSE
ELSE 'N/A'
END as sales_meets_expectations
FROM sales s;Na podstawie danych sprzedażowych (tabela SALES) wyświetl liczbę sprzedanych produktów (kolumna SALES_QTY) dla produktu o nazwie 'Product 1', podzieloną na miesiące w 2020 r. (miesiąc w kolumnie SALES_DATE). W kolumnach wyników dodaj kolumnę exceeded_expected_needs z wartością „Y” dla wierszy, w których łączna liczba sprzedanych produktów jest większa niż 1500, w przeciwnym razie wartości dla tej kolumny powinny wynosić „N”. #praktyka #składnia #join
SELECT EXTRACT(MONTH FROM s.sales_date),
SUM(s.sales_qty),
CASE
WHEN sum(s.sales_qty) > 1500 THEN 'Y'
ELSE 'N'
END as exceeded_expected_needs
FROM sales s
JOIN products p ON p.product_id = s.product_id
AND p.product_name = 'Product 1'
WHERE EXTRACT(YEAR FROM s.sales_date) = 2020
GROUP BY EXTRACT(MONTH FROM s.sales_date);Używając operatora EXISTS, określ liczbę unikalnych identyfikatorów produktów (tabele PRODUCTS, kolumny PRODUCT_ID), które nie były zaangażowane w transakcję sprzedaży (tabela SALES). #praktyka #składnia
SELECT COUNT(DISTINCT p.product_id)
FROM products p
WHERE NOT EXISTS (SELECT 1
FROM sales s
WHERE s.product_id = p.product_id);Używając operatora EXISTS, wyświetl wszystkie produkty (tabela PRODUCTS), które wzięły udział w transakcji sprzedaży (tabela SALES). #praktyka #składnia
SELECT p.*
FROM products p
WHERE EXISTS (SELECT 1
FROM sales s
WHERE s.product_id = p.product_id);Używając polecenia DELETE, usuń z tabeli produktów (tabela PRODUCTS) wszystkie produkty, które do tej pory nie brały udziału w transakcji sprzedaży (tabela SALES). #praktyka #składnia
-- OPCJA 1
WITH products_to_delete AS (
SELECT p.product_id
FROM products p
LEFT JOIN sales s ON s.product_id = p.product_id
WHERE s.id IS NULL
)
DELETE
FROM products p
USING products_to_delete pd
WHERE p.product_id = pd.product_id;
-- OPCJA 2
DELETE
FROM products p
WHERE p.product_id IN (SELECT p.product_id
FROM products p
LEFT JOIN sales s ON s.product_id = p.product_id
WHERE s.id IS NULL);Używając polecenia DELETE, usuń wszystkie dane z tabeli produktów (tabela PRODUCTS), w której opis produktu (kolumny RANDOM_DESC) rozpoczyna się od „c4c”. #praktyka #składnia
DELETE
FROM products p
WHERE p.random_desc LIKE 'c4c%';Na podstawie danych sprzedażowych (tabela SALES) utwórz dwa zestawy danych (2x SELECT) dla produktów, które zostały sprzedane w miesiącu A i miesiącu B tego samego roku (wybierz miesiące według własnego uznania na podstawie kolumny SALES_DATE). Wynik musi zawierać tylko wiersze o unikalnych nazwach produktów (kolumna PRODUCT_NAME). Następnie, używając operacji UNION, połącz oba zestawy i wyświetl nazwy produktów (kolumna PRODUCT_NAME), które brały udział w transakcjach sprzedaży. #praktyka #składnia
SELECT DISTINCT p.product_name
FROM sales s
JOIN products p ON s.product_id = p.product_id
AND EXTRACT(MONTH FROM s.sales_date) = 7
AND EXTRACT(YEAR FROM s.sales_date) = 2020
UNION
SELECT DISTINCT p.product_name
FROM sales s
JOIN products p ON s.product_id = p.product_id
AND EXTRACT(MONTH FROM s.sales_date) = 8
AND EXTRACT(YEAR FROM s.sales_date) = 2020;Usuń wszystkie dane sprzedażowe (tabele SALES), zakładając, że operacja ma być nieodwracalna.
TRUNCATE TABLE sales;
-- or when other objects references SALES
TRUNCATE TABLE sales CASCADE;Utwórz nową tabelę PRODUCTS_OLD_WAREHOUSE z tymi samymi kolumnami, co istniejąca tabela produktów (tabela PRODUCTS). Wstaw kilka wierszy do nowej tabeli — dowolne wiersze. Używając operacji UNION i UNION ALL, połącz tabelę PRODUCTS_OLD_WAREHOUSE z dowolnymi 10 produktami z tabeli PRODUCTS, a wynik wyświetli tylko nazwę produktu (kolumna PRODUCT_NAME) i kategorię produktu (kolumna PRODUCT_CATEGORY). Czy pominięto jakieś wiersze podczas używania UNION? #praktyka #składnia
CREATE TABLE products_old_warehouse AS
SELECT *
FROM products;
TRUNCATE TABLE products_old_warehouse;
INSERT INTO products_old_warehouse
SELECT *
FROM products
LIMIT 5;
SELECT pod.product_name,
pod.product_category
FROM products_old_warehouse pod
UNION
SELECT p.product_name,
p.product_category
FROM products p
LIMIT 10;
SELECT pod.product_name,
pod.product_category
FROM products_old_warehouse pod
UNION ALL
SELECT p.product_name,
p.product_category
FROM products p
LIMIT 10;Utwórz widok sales_with_amount_more_then_10 (CREATE VIEW) na podstawie tabeli z danymi sprzedaży, gdzie sprzedaż jest większa niż 10 (tabela SALES). Następnie spróbuj usunąć tabelę SALES za pomocą zwykłej operacji DROP i opcji CASCADE?. #praktyka #składnia
CREATE VIEW sales_with_amount_more_then_10 AS
SELECT *
FROM sales
WHERE sales_amount >10;
DROP TABLE sales; //błąd, ponieważ istnieje zależny widok
DROP TABLE sales CASCADE; // sukces, ale widok sales_with_amount_more_then_10 również zostanie usuniętyUtwórz widok products_sold na podstawie tabel produktów PRODUCTS i tabel danych sprzedaży SALES. Widok powinien mieć 4 kolumny: sales_date, sales_amount, product_name i product_category. #praktyka #składnia
CREATE OR REPLACE VIEW products_sold AS
SELECT s.sales_date
, s.sales_amount
, p.product_name
, p.product_category
FROM sales s
JOIN products p on p.product_id = s.product_id;Utwórz widok zmaterializowany products_sold na podstawie tabel produktów PRODUCTS i tabel danych sprzedaży SALES. Widok powinien mieć 4 kolumny: sales_date, sales_amount, product_name i product_category. #praktyka #składnia
CREATE MATERIALIZED VIEW products_sold AS
SELECT s.sales_date
, s.sales_amount
, p.product_name
, p.product_category
FROM sales s
JOIN products p on p.product_id = s.product_id;Na podstawie wszystkich produktów (tabela PRODUCTS) utwórz listę nazw produktów (kolumna PRODUCT_NAME) i tablicę unikalnych kategorii (kolumna PRODUCT_CATEGORY). Do której kategorii należą te produkty? #praktyka #składnia
SELECT product_name,
array_agg(DISTINCT product_category) as categories_list
FROM products
GROUP BY product_name;Na podstawie danych sprzedażowych (tabela SALES) wyświetl wszystkie transakcje sprzedaży z następnego miesiąca (dane testowe utworzone jako INTERVAL, stąd kolejny miesiąc), tak aby uzyskane dane pokazywały całkowitą wartość sprzedaży (kolumny SALES_AMOUNT), całkowitą liczbę sprzedanych jednostek (kolumna SALES_QTY), dla nazw produktów (kolumna PRODUCT_NAME) wraz z tablicą unikalnych kategorii, do których należą te produkty. #ćwiczenie #składnia
SELECT ROUND(SUM(sales_amount)) as total_sales,
ROUND(SUM(sales_qty)) as total_qty_sold,
p.product_name,
ARRAY_AGG(DISTINCT p.product_category) as product_categories_list
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE EXTRACT(MONTH FROM sales_date) = 8
AND EXTRACT(YEAR FROM sales_date) = 2020
GROUP BY EXTRACT(YEAR FROM sales_date)||''||EXTRACT(MONTH FROM sales_date)
, p.product_name;Jakiego polecenia można użyć, aby przyznać użytkownikowi user_limited_access uprawnienia do odczytu danych z tabeli SALES? #praktyka #składnia
GRANT SELECT ON sales TO user_limited_access;Jakiego polecenia można użyć, aby przyznać użytkownikowi user_limited_access wszystkie uprawnienia do tabeli SALES? #praktyka #składnia
GRANT ALL PRIVILEGES ON sales TO user_limited_access;Jakiego polecenia można użyć, aby przyznać użytkownikowi user_limited_access uprawnienia do odczytu kolumny sales_date i aktualizowania danych w kolumnie discount w tabeli SALES. #praktyka #składnia
GRANT SELECT (sales_date), UPDATE (discount) ON sales TO user_limited_access;Jakiego polecenia można użyć, aby odwołać user_limited_access w celu odczytu danych z tabeli SALES. #praktyka #składnia
REVOKE SELECT ON sales FROM user_limited_access;Jakiego polecenia można użyć, aby odwołać uprawnienia user_limited_access do wszystkich tabel w schemacie PUBLIC_SALES (zakładając, że taki schemat istnieje w bazie danych). #praktyka #składnia
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA public_sales FROM user_limited_access;Jeśli masz rolę (zestaw uprawnień) w bazie danych o nazwie limited_access (umożliwiającą ograniczony dostęp do bazy danych), nadaj użytkownikowi user_limited_access tę rolę. #praktyka #składnia
GRANT limited_access TO user_limited_access;Użytkownikowi user_limited_access przypisano rolę limited_access (udzielającą ograniczonego dostępu do bazy danych), odwołaj dostęp użytkownika do tej roli. #praktyka #składnia
REVOKE limited_access TO user_limited_access;Zakładając, że pracujesz w sesji bazy danych bez aktywnego COMMIT (bez opcji AUTOCOMMIT), utwórz dwa zapytania. Pierwsze z nich usunie wszystkie rekordy z tabeli PRODUCTS, tak aby nazwa produktu (kolumna PRODUCT_NAME) była równa Product 1. Drugie z nich wycofa zmiany wprowadzone przez pierwsze zapytanie. #praktyka #składnia
DELETE FROM products p WHERE p.product_name = 'Product 1';
ROLLBACK;Posiadanie tabeli z historycznymi produktami, PRODUCTS_HISTORY, o tej samej strukturze (te same kolumny i typy danych) co tabela PRODUCTS. Wstaw wszystkie dane z tabeli PRODUCTS_HISTORY do tabeli PRODUCTS w jednym zapytaniu. #praktyka #składnia
INSERT INTO products
SELECT * FROM products_history;Wyświetl wszystkie informacje o produkcie (tabele PRODUCTS) poprzez dodanie kolumny product_name_category do zestawu wyników, która będzie połączeniem nazwy produktu (kolumna PRODUCT_NAME) i kategorii produktu (kolumna PRODUCT_CATEGORY). Oddziel wartości znakiem ' - '. W przypadku niezdefiniowanej wartości dla jednego lub obu atrybutów wstaw pusty tekst ''. #praktyka #składnia
SELECT p.*,
COALESCE(p.product_name,'')||' - '||COALESCE(p.product_category,'') as product_name_category
FROM products p;
--- lub z użyciem funkcji CONCAT
SELECT p.*,
CONCAT(COALESCE(p.product_name,''),
' - ',
COALESCE(p.product_category,'')
) as product_name_category
FROM products p;Jaki będzie wynik tego zapytania? SELECT product_name FROM products ORDER BY 2 DESC; #praktyka #składnia
ORDER BY 2 zadziała, gdy w zestawie wyników będą co najmniej 2 kolumny, a następnie zapytanie użyje drugiej kolumny (w SELECT) do wykonania sortowania.
Jednak w powyższym przykładzie baza danych zwróci błąd, ponieważ w zestawie wyników nie ma drugiego elementu (w SELECT jest tylko SELECT product_name).
Bez używania funkcji MIN wyświetl najmniejszy identyfikator produktu (kolumna PRODUCT_ID) w tabeli PRODUCTS. #praktyka #składnia
SELECT product_id
FROM products
ORDER BY product_id LIMIT 1;Bez używania funkcji MAX wyświetl drugi co do wielkości identyfikator produktu (kolumna PRODUCT_ID) w tabeli PRODUCTS. #praktyka #składnia
SELECT product_id
FROM products
ORDER BY product_id DESC
LIMIT 1
OFFSET 1;Na podstawie danych produktu (tabela PRODUCTS) znajdź wszystkie produkty, które powtarzają się w innych atrybutach produktu (produkty, które pojawiają się więcej niż raz). #praktyka #składnia
SELECT product_name
, count(*)
FROM products
GROUP BY product_name
HAVING count(*) > 1;Wyświetl wszystkie nazwy produktów (kolumna PRODUCT_NAME) wraz z łączną wartością sprzedaży (kolumna SALES_AMOUNT), np. średnia liczba sprzedanych jednostek (kolumna SALES_QTY) jest większa niż 5. #praktyka #składnia
SELECT p.product_name
, SUM(s.sales_amount)
FROM sales s
JOIN products p ON p.product_id = s.product_id
GROUP BY p.product_name
HAVING AVG(s.sales_qty) > 5;Wyświetl łączną sprzedaż (kolumna SALES_AMOUNT) dla produktu 'Product 1' (kolumna PRODUCT_NAME), z 'Category 1' (kolumna PRODUCT_CATEGORY), grupując dane według nowego atrybutu YEAR_MONTH. Atrybut powinien być połączeniem roku i miesiąca dla daty sprzedaży (kolumna SALES_DATE). #praktyka #składnia
SELECT p.product_name
, EXTRACT(YEAR FROM s.sales_date) ||''|| EXTRACT(MONTH FROM s.sales_date) as year_month
, SUM(s.sales_amount) as total_sales
FROM sales s
JOIN products p ON p.product_id = s.product_id
AND p.product_name = 'Product 1'
AND p.product_category = 'Category 1'
GROUP BY p.product_name, 2
ORDER BY 2 DESC;Wyświetl całkowity wzrost sprzedaży (kolumna SALES_AMOUNT) dla „Produktu 1” (kolumna PRODUCT_NAME), z „Kategorii 1” (kolumna PRODUCT_CATEGORY), grupując dane według nowego atrybutu YEAR_MONTH. W taki sposób, aby kolejne wartości sprzedaży wskazywały sumę bieżącej i poprzedniej wartości sumy sprzedaży dla roku i miesiąca. #praktyka #składnia
SELECT DISTINCT
p.product_name
, EXTRACT(YEAR FROM s.sales_date) ||''|| EXTRACT(MONTH FROM s.sales_date) as year_month
, SUM(s.sales_amount) OVER (ORDER BY EXTRACT(YEAR FROM s.sales_date) ||''|| EXTRACT(MONTH FROM s.sales_date) desc) as rolling_sum_of_sales
FROM sales s
JOIN products p ON p.product_id = s.product_id
AND p.product_name = 'Product 1'
AND p.product_category = 'Category 1'
ORDER BY 2 DESC;Czy i jak użyć kolejności kolumn składni SELECT w części ORDER BY zapytania. #praktyka #składnia
Składnia ORDER BY jest ostatnim elementem „logicznego” planu wykonania zapytania. Stąd, gdy używamy aliasów dla kolumn w składni SELECT (ponieważ na przykład są to kolumny zbudowane na funkcjach), możemy użyć tych aliasów w ORDER BY.
SELECT p.product_name,
LEFT(p.random_desc, 5) as desc_small
FROM products p
ORDER BY desc_small; SELECT p.product_name,
LEFT(p.random_desc, 5) as desc_small
FROM products p
ORDER BY 2;Czy można posortować oddzielnie zestawy używane w składni UNION lub UNION ALL. #praktyka #składnia
Tak i nie 🙂
Domyślnie ORDER BY jest używane do sortowania całego zestawu wyników, więc będzie ostatnim elementem składni SELECT po UNION lub UNION ALL.
Możesz jednak oddzielnie posortować zestawy używane w UNION / UNION ALL, używając podzapytań (tj. traktując oba zestawy jako podzapytania) lub wstawiając sztuczną kolumnę i początkowo sortując według niej. Podczas korzystania z podejścia ze sztuczną kolumną uważaj na wyniki, UNION, które eliminuje wiersze o tych samych wartościach podczas łączenia, nie będzie miało zastosowania, ponieważ sztuczna kolumna zawsze będzie inna w zestawach (tj. na końcu dodatkowe podzapytanie + distinct).
-- ORDER BY ostatni element
SELECT p.product_name
FROM products p
WHERE p.product_category = 'Category 1'
UNION
SELECT p.product_name
FROM products p
WHERE p.product_category = 'Category 2'
ORDER BY product_name;
-- ORDER BY wewnątrz podzapytania
SELECT sq.product_name
FROM (SELECT p.product_name
FROM products p
WHERE p.product_category = 'Category 1'
ORDER BY p.product_name) sq
UNION
SELECT p.product_name
FROM products p
WHERE p.product_category = 'Category 2';
-- ORDER BY po 'sztucznej' kolumne 'orderCol'
SELECT p.product_name
, 1 as orderCol
FROM products p
WHERE p.product_category = 'Category 1'
UNION
SELECT p.product_name
, 2 as orderCol
FROM products p
WHERE p.product_category = 'Category 2'
ORDER BY orderCol, product_name;Używając funkcji okna rank() over(), wyświetl nazwy produktów (kolumna PRODUCT_NAME) i ich łączną sprzedaż (kolumny SALES_AMOUNT) za sierpień 2020 (kolumna SALES_DATE) oraz ich ranking od najlepiej sprzedającego się produktu. #praktyka #składnia
SELECT *
, rank() over (order by sales_total desc) as rank
FROM (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name) sq;Używając funkcji lag() over() window, oblicz różnicę w całkowitej sprzedaży (kolumna SALES_AMOUNT) pomiędzy kolejnymi (według wartości sprzedaży od najwyższej) produktami w miesiącu sierpniu 2020 (kolumny SALES_DATE). W rezultacie wyświetl nazwę produktu (kolumna PRODUCT_NAME), całkowitą sprzedaż i różnicę sprzedaży. Przykład: Produkt 1, sprzedaż 100 (najwyższa) Różnica: 0. Produkt 3, Sprzedaż 80, Różnica: 20 (w stosunku do Produktu 1). Produkt 5, Sprzedaż: 50, Różnica: 30 (w porównaniu do Produktu 3) itd. #praktyka #składnia
SELECT *
, COALESCE(lag(sales_total) over (order by sales_total desc) - sales_total,0) as sales_diff
FROM (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name) sq;Używając funkcji okna first_value() over(), oblicz różnicę w całkowitej sprzedaży (kolumna SALES_AMOUNT) pomiędzy najlepszą sprzedażą a sprzedażą danego produktu w miesiącu sierpniu 2020 (kolumny SALES_DATE). W rezultacie wyświetl nazwę produktu (kolumna PRODUCT_NAME), całkowitą sprzedaż i różnicę sprzedaży. Przykład: Produkt 1, sprzedaż 100 (najwyższa) Różnica: 0. Produkt 3, Sprzedaż 80, Różnica: 20 (w stosunku do Produktu 1). Produkt 5, Sprzedaż: 50, Różnica: 50 (w porównaniu do Produktu 1) itd. #praktyka #składnia
SELECT *
, first_value(sales_total) over (order by sales_total desc) - sales_total as sales_diff
FROM (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p ON p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name) sq;Używając funkcji okna first_value() over() i last_value() over(), oblicz różnicę w całkowitej sprzedaży (kolumna SALES_AMOUNT) według nazwy produktu (kolumna PRODUCT_NAME), pomiędzy najwyższą a najniższą sprzedażą w sierpniu 2020 (kolumny SALES_DATE). Wyświetl w wyniku tylko tę różnicę. #praktyka #składnia
SELECT first_value(sales_total) over (order by sales_total desc) - last_value(sales_total) over () as sales_diff
FROM (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name) sq
LIMIT 1;Używając funkcji MIN() i MAX(), oblicz różnicę w całkowitej sprzedaży (kolumna SALES_AMOUNT) według nazwy produktu (kolumna PRODUCT_NAME), pomiędzy najwyższą i najniższą sprzedażą w miesiącu sierpniu 2020 (kolumny SALES_DATE). Wyświetl w wyniku tylko tę różnicę. #praktyka #składnia
SELECT max(sales_total) - min(sales_total) as sales_diff
FROM (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name) sq;Bez używania funkcji min() i max() lub last_value() i first_value(), oblicz różnicę w całkowitej sprzedaży (kolumna SALES_AMOUNT) według nazwy produktu (kolumna PRODUCT_NAME), pomiędzy najwyższą i najniższą sprzedażą w miesiącu sierpniu 2020 (kolumny SALES_DATE). Wyświetl w wyniku tylko tę różnicę. #praktyka #składnia
WITH sales_total_august_2020 AS (
SELECT p.product_name
, sum(s.sales_amount) as sales_total
FROM sales s
JOIN products p on p.product_id = s.product_id
WHERE extract(month from s.sales_date) = 8
AND extract(year from s.sales_date) = 2020
GROUP BY p.product_name
)
SELECT mas.max_sales - mis.min_sales as sales_diff
FROM (SELECT sales_total as max_sales
FROM sales_total_august_2020
ORDER BY sales_total desc
LIMIT 1) mas
JOIN (SELECT sales_total as min_sales
FROM sales_total_august_2020
ORDER BY sales_total asc
LIMIT 1) mis ON 1=1;Dodaj nową kolumnę tekstową limited_description z limitem 250 znaków do tabeli produktów (tabela PRODUCTS). #praktyka #składnia
ALTER TABLE products ADD COLUMN limited_description varchar(250);Do tabeli z danymi sprzedażowymi (tabela SALES) dodaj nową kolumnę typu TRUE / FALSE, sales_over_200k, co oznacza sprzedaż powyżej 200 000. Kolumna nie może mieć niezdefiniowanych wartości, domyślnie każda wartość powinna być ustawiona na FALSE. #praktyka #składnia
ALTER TABLE sales ADD COLUMN sales_over_200k bool DEFAULT FALSE NOT NULL;Dodaj nową kolumnę tekstową limited_description z limitem 250 znaków do tabeli produktów (tabela PRODUCTS). Dla istniejących danych w tabeli PRODUKTY przygotuje zapytanie UPDATE, które na podstawie istniejących opisów (kolumna RANDOM_DESC) pobierze pierwsze 5 znaków opisu produktu dla każdego wiersza i wstawi je do nowego pola limited_description. #praktyka #składnia
ALTER TABLE products ADD COLUMN limited_description varchar(250);
UPDATE products SET limited_description = left(random_desc,5);Z tabeli zawierającej dane sprzedażowe (tabela SPRZEDAŻ) usuń kolumnę rabatu (kolumna RABAT). #praktyka #składnia
ALTER TABLE sales DROP COLUMN discount;Używając konstrukcji CTAS (CREATE TABLE AS SELECT), utwórz kopię tabeli produktów (tabela PRODUCTS) i nazwij ją PRODUCTS_BP. Do tabeli produktów dodaj nową kolumnę limited_description typu tekstowego o długości 100 znaków. Usuń kolumnę random_desc i wszystkie dane z tabeli produktów, używając składni TRUNCATE. Z kopii tabeli produktów PRODUCTS_BP wstaw dane do tabeli PRODUCTS, do nowej kolumny LIMITED_DESCRIPTION wstaw dane ze starej kolumny RANDOM_DESC, tak aby nowa kolumna była połączeniem pierwszych 5 i ostatnich 5 znaków z poprzedniej kolumny. Po zakończeniu operacji usuń tabelę PRODUCTS_BP. #praktyka #składnia
CREATE TABLE products_bp AS
SELECT *
FROM products;
ALTER TABLE products ADD COLUMN limited_description varchar(100);
ALTER TABLE products DROP COLUMN random_desc;
TRUNCATE TABLE products;
INSERT INTO products (product_id, product_name, product_category, limited_description)
SELECT product_id
, product_name
, product_category
, left(random_desc,5)||right(random_desc,5) as limited_description
FROM products_bp;
DROP TABLE products_bp;Utwórz indeks sales_prd_id_idx dla kolumny PRODUCT_ID w tabeli z danymi sprzedażowymi (tabela SALES). Indeks powinien być typu B-TREE. #praktyka #składnia
CREATE INDEX sales_prd_id_idx ON sales USING btree (product_id);Utwórz indeks sales_prd_id_idx dla kolumny PRODUCT_ID w tabeli danych sprzedaży (tabela SALES). Indeks powinien być typu B-TREE, tabela nie powinna być zablokowana podczas tworzenia indeksu. Uwaga: dotyczy bazy danych PostgreSQL. #praktyka #syntax
CREATE INDEX CONCURRENTLY sales_prd_id_idx ON sales USING btree (product_id);Utwórz indeks sales_prd_id_idx dla kolumny PRODUCT_ID w tabeli danych sprzedaży (tabela SALES). Indeks powinien być typu B-TREE, metoda sortowania danych dla indeksu powinna wskazywać, że niezdefiniowane wartości (NULL) są brane jako pierwsze do sortowania. #praktyka #składnia
CREATE INDEX sales_prd_id_idx ON sales USING btree (product_ID NULLS FIRST);Utwórz index limited_prd_desc_idx z funkcją wybierania pierwszych 5 znaków opisu produktu (kolumna RANDOM_DESC) dla danych produktu (tabela PRODUCTS). Wyrażenie powinno używać funkcji LEFT. #praktyka #składnia #ddl
CREATE INDEX limited_prd_desc_idx ON products (left(random_desc,5));Usuń indeks sales_prd_id_idx dla kolumny PRODUCT_ID z tabeli z danymi sprzedaży (tabela SALES), jeśli taki indeks istnieje. W taki sposób, aby zapytanie nie zwróciło błędu, jeśli indeks nie istnieje. #praktyka #składnia #ddl
DROP INDEX IF EXISTS sales_prd_id_idx;Korzystając z planu zapytania, sprawdź, jaka będzie różnica w przypadku zapytania, którego celem jest wyświetlenie danych produktu o nazwie Produkt 1 (kolumna PRODUCT_NAME) z istniejącym indeksem B-TREE w atrybucie nazwy produktu i bez niego. #praktyka #składnia #performance
-- Bez Indeksu
EXPLAIN ANALYZE
SELECT *
FROM products
WHERE product_name = 'Product 1';
QUERY PLAN
Seq Scan on products (cost=0.00..10.88 rows=1 width=1068) (actual time=0.014..0.141 rows=104 loops=1)
Filter: ((product_name)::text = 'Product 1'::text)
Rows Removed by Filter: 896
Planning time: 0.049 ms
Execution time: 0.156 ms
-- Z Indeksem
CREATE INDEX prd_product_name_idx ON products (product_name);
EXPLAIN ANALYZE
SELECT *
FROM products
WHERE product_name = 'Product 1';
QUERY PLAN
Index Scan using prd_product_name_idx on products (cost=0.27..8.29 rows=1 width=1068) (actual time=0.022..0.057 rows=99 loops=1)
Index Cond: ((product_name)::text = 'Product 1'::text)
Planning time: 0.248 ms
Execution time: 0.083 msSprawdź za pomocą planu zapytania, jaki typ połączenia fizycznego zostanie użyty podczas łączenia danych sprzedażowych (tabela SALES) z danymi produktu (tabela PRODUCTS), po kluczu łączenia PRODUCT_ID, używając łączenia INNER JOINb>. #praktyka #składnia #performance
EXPLAIN ANALYZE
SELECT *
FROM sales s
JOIN products p ON p.product_id = s.product_id;
QUERY PLAN
Hash Join (cost=11.57..181.31 rows=1942 width=1148) (actual time=0.274..4.998 rows=9894 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..129.50 rows=5550 width=80) (actual time=0.021..1.291 rows=10000 loops=1)
-> Hash (cost=10.70..10.70 rows=70 width=1068) (actual time=0.224..0.224 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 80kB
-> Seq Scan on products p (cost=0.00..10.70 rows=70 width=1068) (actual time=0.007..0.091 rows=1000 loops=1)
Planning time: 0.213 ms
Execution time: 5.598 msPrzygotuj zapytanie, w którym metoda złączenia MERGE JOIN zostanie użyta do połączenia danych sprzedażowych (tabela SALES) z danymi produktów (tabela PRODUCTS) po kluczu łączenia PRODUCT_ID, używając łączenia INNER JOIN. #praktyka #składnia #performance
EXPLAIN ANALYZE
SELECT *
FROM (SELECT *
FROM products
ORDER BY product_id) p
JOIN (SELECT *
FROM sales
ORDER BY product_id) s ON s.product_id = p.product_id;
QUERY PLAN
Merge Join (cost=909.80..1184.70 rows=10000 width=97) (actual time=3.176..7.206 rows=9894 loops=1)
Merge Cond: (products.product_id = sales.product_id)
-> Sort (cost=69.83..72.33 rows=1000 width=41) (actual time=0.227..0.239 rows=100 loops=1)
Sort Key: products.product_id
Sort Method: quicksort Memory: 103kB
-> Seq Scan on products (cost=0.00..20.00 rows=1000 width=41) (actual time=0.011..0.104 rows=1000 loops=1)
-> Materialize (cost=838.39..988.39 rows=10000 width=56) (actual time=2.896..5.254 rows=10000 loops=1)
-> Sort (cost=838.39..863.39 rows=10000 width=56) (actual time=2.892..4.305 rows=10000 loops=1)
Sort Key: sales.product_id
Sort Method: quicksort Memory: 1166kB
-> Seq Scan on sales (cost=0.00..174.00 rows=10000 width=56) (actual time=0.007..0.835 rows=10000 loops=1)
Planning time: 0.359 ms
Execution time: 7.712 msUżywając planu zapytania, sprawdź, jaka będzie różnica w przypadku zapytania, którego celem jest wyświetlenie danych produktu (tabela PRODUCTS) dla produktów, których nazwa jest inna niż (≠ lub <>) Produkt 1 (kolumna PRODUCT_NAME) z indeksem B-TREE dla nazwy produktu i bez niego. Czy indeks zostanie użyty? #praktyka #składnia #performance
-- Bez Indeksu
EXPLAIN ANALYZE
SELECT *
FROM products
WHERE product_name <> 'Product 1';
QUERY PLAN
Seq Scan on products (cost=0.00..22.50 rows=896 width=41) (actual time=0.022..0.646 rows=896 loops=1)
Filter: ((product_name)::text <> 'Product 1'::text)
Rows Removed by Filter: 104
Planning time: 0.811 ms
Execution time: 0.908 ms
-- Z Indeksem
CREATE INDEX prd_product_name_idx ON products (product_name);
EXPLAIN ANALYZE
SELECT *
FROM products
WHERE product_name <> 'Product 1';
QUERY PLAN
Seq Scan on products (cost=0.00..22.50 rows=901 width=41) (actual time=0.016..0.286 rows=901 loops=1)
Filter: ((product_name)::text <> 'Product 1'::text)
Rows Removed by Filter: 99
Planning time: 0.335 ms
Execution time: 0.353 msUżywając planu zapytania, sprawdź, czy w przypadku zapytania łączącego dane sprzedażowe (tabela SALES) z danymi produktu (tabela PRODUCTS) na podstawie klucza łączenia PRODUCT_ID i dla sprzedaży większej niż 5 (kolumna SALES_AMOUNT) zostaną użyte indeksy utworzone w kolumnach PRODUCT_ID obu tabel (SALES i PRODUCT). #praktyka #składnia #performance
EXPLAIN ANALYZE
SELECT *
FROM sales s
JOIN products p ON s.product_id = p.product_id
AND s.sales_amount > 5;
QUERY PLAN
Hash Join (cost=11.57..168.37 rows=648 width=1148) (actual time=0.443..7.010 rows=6031 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..143.38 rows=1850 width=80) (actual time=0.018..3.469 rows=6086 loops=1)
Filter: (sales_amount > '5'::numeric)
Rows Removed by Filter: 3914
-> Hash (cost=10.70..10.70 rows=70 width=1068) (actual time=0.388..0.388 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 80kB
-> Seq Scan on products p (cost=0.00..10.70 rows=70 width=1068) (actual time=0.007..0.155 rows=1000 loops=1)
Planning time: 0.494 ms
Execution time: 7.424 msNa podstawie danych produktowych (tabela PRODUCTS) znajdź wszystkie produkty, których opis produktu (kolumna RANDOM_DESC) jest dłuższy niż 10 znaków. #praktyka #składnia
SELECT p.*
FROM products p
WHERE length(p.random_desc) > 10;Utwórz dwa równoważne (w kontekście zestawów wyników) zapytania. Oba zapytania powinny być kombinacją danych sprzedażowych (tabela SALES) i danych produktowych (tabela PRODUCTS). W pierwszym zapytaniu JOIN powinien być typu INNER JOIN po kluczu łączenia PRODUCT_ID. W drugim zapytaniu JOIN powinien być typu LEFT OUTER JOIN po kluczu łączenia PRODUCT_ID, ale filtrując dane sprzedaży, dla których nie ma informacji o produkcie z tabeli PRODUCTS. #praktyka #składnia
SELECT s.*
, p.*
FROM sales s
JOIN products p ON p.product_id = s.product_id;
SELECT s.*
, p.*
FROM sales s
LEFT JOIN products p ON p.product_id = s.product_id
WHERE p.product_ID IS NOT NULL;Używając planu zapytania, sprawdź, które zapytania (na podstawie planu zapytania) zostaną wykonane szybciej. Oba zapytania powinny być kombinacją danych sprzedażowych (tabela SALES) i danych produktowych (tabela PRODUCTS). W pierwszym zapytaniu połączenie powinno być typu INNER JOIN po kluczu łączenia PRODUCT_ID. W drugim zapytaniu połączenie powinno być typu LEFT OUTER JOIN po kluczu łączenia PRODUCT_ID, ale filtrując dane sprzedaży, dla których nie ma informacji o produkcie z tabeli PRODUCTS. Należy zauważyć, że w tej sytuacji oba zapytania powinny zwrócić ten sam zestaw wyników. #praktyka #składnia
EXPLAIN ANALYZE
SELECT s.*
, p.*
FROM sales s
JOIN products p ON p.product_id = s.product_id;
QUERY PLAN
Hash Join (cost=32.50..344.00 rows=10000 width=97) (actual time=0.260..3.872 rows=9893 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=56) (actual time=0.010..0.789 rows=10000 loops=1)
-> Hash (cost=20.00..20.00 rows=1000 width=41) (actual time=0.228..0.228 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 80kB
-> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=41) (actual time=0.007..0.084 rows=1000 loops=1)
Planning time: 0.316 ms
Execution time: 4.302 ms
EXPLAIN ANALYZE
SELECT s.*
, p.*
FROM sales s
LEFT JOIN products p ON p.product_id = s.product_id
WHERE p.product_ID IS NOT NULL;
QUERY PLAN
Hash Join (cost=32.50..344.00 rows=10000 width=97) (actual time=0.267..3.655 rows=9893 loops=1)
Hash Cond: (s.product_id = p.product_id)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=56) (actual time=0.009..0.852 rows=10000 loops=1)
-> Hash (cost=20.00..20.00 rows=1000 width=41) (actual time=0.241..0.241 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 80kB
-> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=41) (actual time=0.006..0.139 rows=1000 loops=1)
Filter: (product_id IS NOT NULL)
Planning time: 0.084 ms
Execution time: 4.072 msSprawdź, korzystając z planu zapytania, jaki typ fizycznego łączenia danych zostanie użyty w przypadku zapytania, którego celem jest połączenie danych sprzedażowych (tabela SALES) i danych produktowych (tabela PRODUCTS) za pomocą CROSS JOIN. #praktyka #składnia
EXPLAIN ANALYZE
SELECT s.*
, p.*
FROM sales s
JOIN products p ON 1=1;
QUERY PLAN
Nested Loop (cost=0.00..125196.50 rows=10000000 width=97) (actual time=0.028..1980.528 rows=10000000 loops=1)
-> Seq Scan on sales s (cost=0.00..174.00 rows=10000 width=56) (actual time=0.013..2.092 rows=10000 loops=1)
-> Materialize (cost=0.00..25.00 rows=1000 width=41) (actual time=0.000..0.054 rows=1000 loops=10000)
-> Seq Scan on products p (cost=0.00..20.00 rows=1000 width=41) (actual time=0.009..0.097 rows=1000 loops=1)
Planning time: 0.322 ms
Execution time: 2400.225 ms