Data Craze Weekly #6

Tę wiadomość możesz otrzymać bezpośrednio na swoją skrzynkę dzięki zapisowi na newsletter – Data Craze Weekly.
Przegląd Tygodnia
Czym jest Modern Data Stack
Ding, ding, ding! Buzzword detected. Modern Data Stack to chyba najbardziej popularna fraza w świecie danych w ostatnim czasie.
Do czego się tak na prawdę sprowadza?
W zasadzie do stworzenia takiej architektury i sposobu przetwarzania danych, aby zapewnić użytkownik końcowym to czego oni oczekują np. przetwarzanie w czasie prawie rzeczywistym, dobrą wydajność, dostępność danych itp.
Autor ciekawie przechodzi przez zdefniowane elementy Modern Data Stack, opisując ogólnie (bez narzucania wprost konkretnych narzędzi) na co warto zwrócić uwagę.
Jeżeli ta definicja pojawiła się w Twoim kręgu informacji, to ten artykuł pozwoli Ci sensownie poukładać wszystkie klocki związane z Modern Data Stack.
Link: https://medium.com/@bengoswami/how-to-build-a-morden-data-stack-378afbe04c2d
Aktualizacja Hurtowni Danych w AirBnB
Trochę bardziej techniczny artykuł schodzący do poziomu przechowywania danych.
Jakie kroki zaaplikowali inżynierowie z AirBnB aby poprawić wydajność swojej hurtownii.
Jeżeli ciekawią Cię m.in:
- Apache Iceberg
- Apache Spark 3.0
- AQE (Adaptive Query Execution) w Spark
i dlaczego akurat te zmiany wpłynęło na poprawę wydajności w przypadku AirBnB (żeby nie było że są panaceum zawsze i na wszystko), to zerknij do linku poniżej.
A tutaj jeszcze ogólne wnioski:
Comparing the prior TEZ and Hive stack, we see more than 50% compute resource-saving and 40% job elapsed time reduction in our data ingestion framework with Spark 3 and Iceberg. From a usability standpoint, we made it simpler and faster to consume stored data by leveraging Iceberg’s capabilities for native schema and partition evolution.
Link: https://medium.com/airbnb-engineering/upgrading-data-warehouse-infrastructure-at-airbnb-a4e18f09b6d5
5 najpopularniejszych zapytań SQL
Uwaga, trochę clickbait .. 5 najpopularniejszych zapytań SQL faktycznie ale na podstawie zapytań stworzonych w narzędziu SQL Generator 5000 (o którym więcej w sekcji narzędzia).
Nie mniej i tak ciekawie sprawdzić co najczęściej ludzie wyklikują, a są to:
- Korelacje (w SQL funkcja CORR)
- Czyszczenie danych (w narzędziu jako CLEAN ale pod spodem jest to zbiór różnych funkcji np. COALESCE, CAST itp.)
- JOIN 🙂
- Tabele przestawne (PIVOT – jeżeli można z czegoś zrobić Excela to dlaczego by nie skorzystać)
- Agregaty – czyli ogółem zbiór funkcji agregujących dane (np. MAX, SUM, COUNT)
Wnioski autora:
SQL Generator is more popular for automating tedious SQL rather than complex logic
– SQL usage is diverse — in other words, we can’t just learn 5 things and suddenly become experts.
Wszyscy szukamy tego samego, nie ważne czy z SQL-em pracujemy miesiąc czy 10 lat 🙂
Link: https://towardsdatascience.com/the-5-most-popular-sql-transforms-ca1f977ef2b2
Jak nadrobić 5 500 godzin podcastu z pomocą AI
W jaki sposób nadrobić 5500 godzin podcastu, który dodatkowo każdego tygodnia wypuszcza kilka godzin nowego materiału?
Taką zagwozdkę miał autor dołączonego artykułu Enias Cailliau.
Z wykorzystaniem m.in. algorytmów NLP (Natural-Language-Processing), przekształcił ścieżki audio podcastu Joe Rogan, w tekst, który dalej procesował. Tworząc korelacje, czy oceniając wydźwięk (pozytywny / negatywny).
Jak to zrobił technicznie? Sprawdź w artykule.
Link: https://medium.com/steamship/im-consuming-5000-hours-of-joe-rogan-with-the-help-of-ai-9cb7cc7a4985
Narzędzia
SQL Generator 5000 – narzędzie, które pomoże Ci w łatwy sposób wygenerować popularne zapytania SQL, np. agregaty, tabele przestawne itp.
- Tworzysz schemat danych (DDL-a z tabelką)
- Wybierasz składnie SQL (gotową z listy)
- Wypełniasz i klikasz Generate SQL
SQL Generator 5000 przykład:
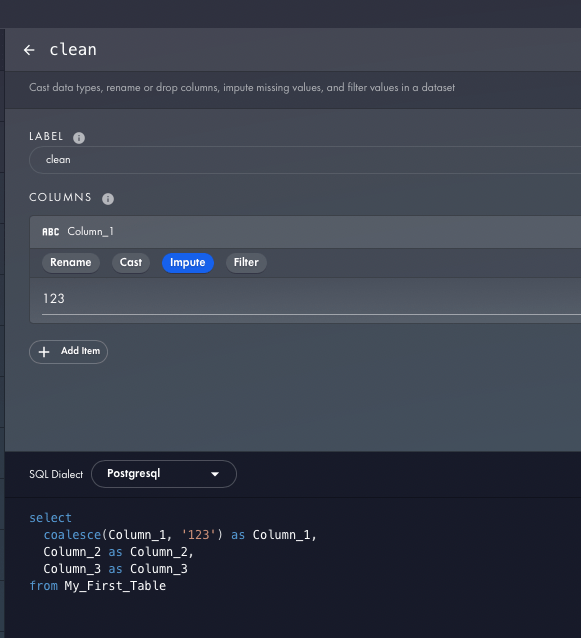
Link: https://app.rasgoml.com/sql
Sprawdź Wiedzę
#SQL
Korzystając ze składni WITH RECURSIVE znajdź wszystkie poprzednie identyfikatory dla identyfikatora „e”. Gdzie relacja poprzedni -> nowy jest zdefiniowana następująco.
Tabela: derived_from, Kolumny: id_previous, id_new.
Wiersze: id_previous: a, id_new: b id_previous: g, id_new: c id_previous: c, id_new: d id_previous: d, id_new: e
ROZWIĄZANIE: https://sqlfiddle.com/#!17/14f08/1
Więcej pytań z SQL znajdziesz: SQL - Q&A
Praca
- Backend Engineer (Python), SIZZLE – Remote EU / North America – USD 50,000 – USD 150,000
Szukane umiejętności: SQL, Python, Spark
- Junior ETL Developer, GreenMinds – Fully Remote – PLN 12,600 – PLN 14,280 (net/month, B2B)
Szukane umiejętności: SQL, Python, Spark