

If you are working daily with PostgreSQL database, sometimes you may have a need to get some information or valid stuff that normally are inside of a Database Administrator scope.
In this article I will share with you 3 useful queries mainly for working with indexes in PostgreSQL, version 9.6+.
Duplicate Indexes
When multiple developers are working on a database and they have a possibility to create indexes, it may be a bit troublesome. There may be a case that one or many indexes will be created for same field (or fields). To check for duplicate indexes you can use query below. It uses standard pg_index results prepared key. One flaw of this query is that if you have more then 4 indexes duplicated it will show only 4, but hopefully it is not your case 🙂
-- Get Duplicated Indexes Information
SELECT pg_size_pretty(SUM(pg_relation_size(idx))::BIGINT) AS SIZE,
(array_agg(idx))[1] AS idx1,
(array_agg(idx))[2] AS idx2,
(array_agg(idx))[3] AS idx3,
(array_agg(idx))[4] AS idx4
FROM (SELECT indexrelid::regclass AS idx,
(indrelid::text ||
E'\n'||
indclass::text ||
E'\n'||
indkey::text ||
E'\n'||
COALESCE(indexprs::text,'')||
E'\n' ||
COALESCE(indpred::text,'')) AS KEY
FROM pg_index) sub
GROUP BY KEY HAVING COUNT(*)>1
ORDER BY SUM(pg_relation_size(idx)) DESC;Query Results:

idx1, idx2 … idx4 are Indexes names that are duplicates on a certain fields.
Indexes With Less Than 300 Scans
Another popular case is when your created index is not being used by query plan, either because of a way data are being queried or due to simple design issue.
With below query, you can verify all non unique (it is important to remove from analysis indexes created on unique keys) indexes with less than 300 scans, on schema different than postgres.
-- Get Information about indexes with less then 300 scans that are not unique
WITH get_schema_names AS (
SELECT schema_name
FROM information_schema.schemata
WHERE schema_owner <> 'postgres'
) SELECT idstat.schemaname AS schema_name,
idstat.relname AS table_name,
indexrelname AS index_name,
idstat.idx_scan AS times_used,
pg_size_pretty(pg_relation_size(idstat.relname::regclass)) AS table_size, pg_size_pretty(pg_relation_size(indexrelname::regclass)) AS index_size,
n_tup_upd + n_tup_ins + n_tup_del AS num_writes,
indexdef AS definition
FROM pg_stat_user_indexes AS idstat
INNER JOIN pg_indexes ON indexrelname = indexname
INNER JOIN pg_stat_user_tables AS tabstat ON idstat.relname = tabstat.relname
INNER JOIN get_schema_names gt ON gt.schema_name = idstat.schemaname
WHERE idstat.idx_scan < 300
AND indexdef !~* 'unique'
ORDER BY idstat.relname, indexrelname;Query Results:

As a result, you will receive information about an index, its size, definition, table size, table name, schema name and usage information.
List Number Of Database Elements
This one is not perfomance specific, but still quite a nifty script to list number of database elements: tables, views, indexes, sequences and special.
-- Get Count of All DB Elements
SELECT n.nspname as schema_name,
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
END as object_type,
count(1) as object_count
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('r','v','i','S','s')
GROUP BY n.nspname,
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
END
ORDER BY n.nspname,
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
END;Query Results:
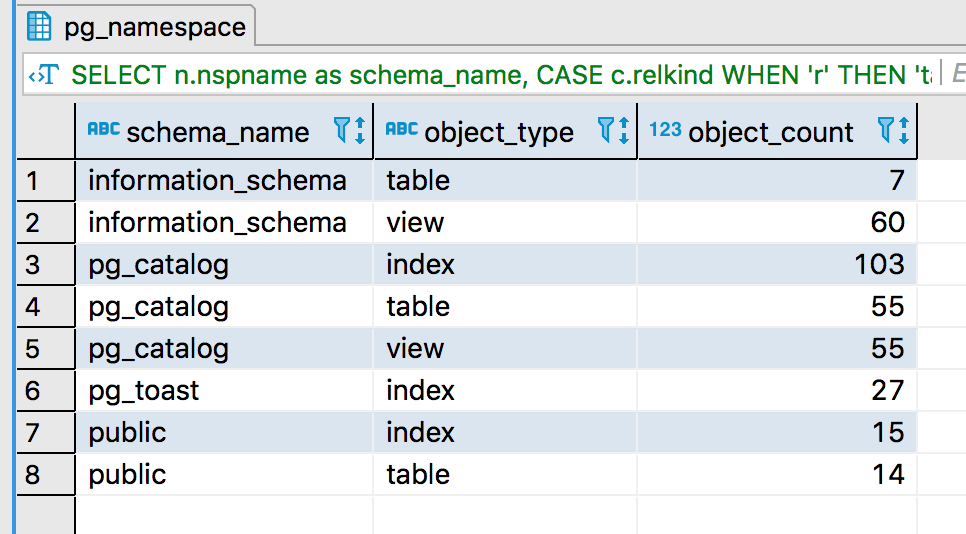
As a results you will see number of mentioned elements for specific schema.
This is Part 1 and if so, there will be Part 2. With in depth information about tables and indexes in your database.
Thanks,
Krzysiek