

Mogłoby się wydawać, że ponad dekadę temu, kiedy sam zaczynałem przygodę z danymi, było łatwiej. Stanowisk w IT związanych z przetwarzaniem danych nie było tak wiele, głównie na rynku można było spotkać SQL Developerów, Programistów Hurtowni Danych, Developerów Business Intelligence.
Czas płynie, technologie się zmieniają, podobnie jak nazwy stanowisk, dzisiaj często na rynku spotkamy Inżynierów Danych (Data Engineer), Analityków Danych (Data Analytics) czy specjalistów z obszaru Business Intelligence.
Jak się w tym wszystkim nie pogubić, od czego zacząć? Na co warto zwrócić uwagę, gdy chcemy rozpocząć przygodę z danymi w nowej dekadzie? Na te i inne pytania spróbujemy sobie odpowiedzieć w tym artykul.
TL;DR
W 3 zdaniach podsumowanie: Zacznij od SQL-a + podstaw relacyjnych i nierelacyjnych baz danych. Patrz jak „duzi’ gracze budują architekturę. Zastanów się czego tak naprawdę Twój biznes chce, i postaraj się im to dostarczyć w przejrzystej formie używając „odpowiednich” (tj. właściwych do właściwego zadania) narzędzi.
Jak Zacząć Przygodę Z Danymi
Zacznijmy od podziału obszaru danych na 3 warstwy:
- inżynieria danych (data engineering)
- analityka i wizualizacja danych
- data science + uczenie maszynowe
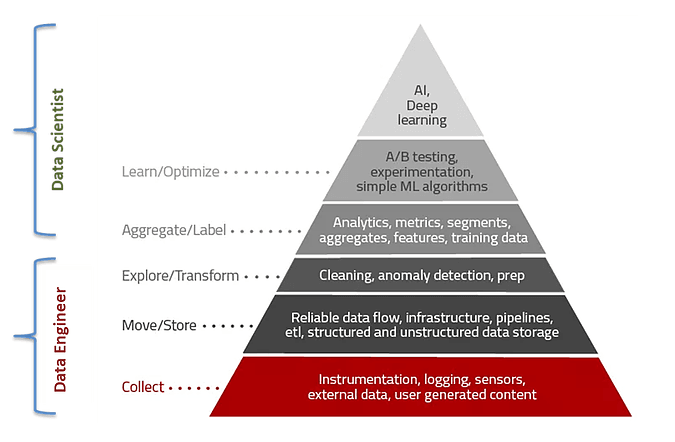
W każdej z nich zdefiniuje: podstawy, materiały i rzeczy które warto śledzić.
DATA ENGINEERING
Inżynieria danych w mniejszym, a często w większym stopniu przyda się każdemu kto chce pracować z danymi. Jaki jest jej cel? Dość prosty, to serce Twojego systemu danych. To z jej pomocą pompujesz dane z różnych źródeł, dokonujesz transformacji, dbasz o jakość i o to żeby wszystko wykonało się na czas. Bez solidnej inżynierii danych, budowanie sensownych modeli analitycznych, podejmowanie biznesowych decyzji w oparciu o wizualizacje, czy podejście do tematu data science, nie ma większego sensu.
Do terminologii z jaką spotkasz się w tej części należą: hurtownie danych, big data, procesy ETL-owe (Extract – Transform – Load) lub ELT (Extract – Load – Transform), strumieniowanie danych (data streaming), kolejki, scheduling (planowanie przetwarzania) itp.
Uwaga: w ofertach pracy znajdziesz sporo chwytliwych haseł (brzmiących niekiedy jak nazwy Pokemonów), związanych z technologiami używanymi w tej warstwie. Niech Cię to nie zmyli. Technologie są ważne, ale nie najważniejsze. Jak wszystko w świecie IT tak i one się zmieniają, ale podstawy, koncepcje i pewne dobre praktyki architektoniczne, długo zostają fundamentalne.
Dlatego też, w tej ale też i w kolejnych warstwach, najważniejsze będą dla mnie kluczowe elementy. Elementy, które pozwolą Ci na zbudowanie solidnej podstawy do dalszego rozwoju.
DATA ENGINEERING – PODSTAWY
SQL
Słyszysz te pomruki, szeptanie i oznaki niedowierzania? “SQL umarł”, “SQL-a to teraz każdy zna”, “NoSQL to jest przyszłość” wołają specjaliści z różnych stron, być może “ale nie uprzedzajmy faktów”.
Ponad 10 lat pracuję z danymi, na różnych stanowiskach w różnych firmach – głównie sporych zagranicznych korporacjach. Jedno wiem na pewno – „SQL jest król danych, tak jak Lew jest król dżungli”.
Język w swoich podstawach jest prostszy i logiczny co czyni go łatwo dostępnym dla różnych stanowisk nie tylko stricte związanych z IT. Jest z nami prawie tak długo jak same bazy relacyjne – grubo ponad 3 dekady – 1986.
Nie ignoruj go, nawet jeżeli SELECT-y nie będą Twoją codziennością, ilość przypadkowych (a może lepiej nieprzypadkowych) miejsc w których okaże się pomocny jest ogromna. Głównie w miejscach gdzie “pod spodem” znajdują się relacyjne źródła danych (relacyjne bazy danych – systemy ERP / CRM / Hurtownie Danych),
Relacyjne Bazy Danych – główne koncepcje + architektura wybranej bazy np. PostgreSQL
Podobnie jak z SQL-em – to się nie skaluje, relikt z lat 70-tych. Bazy NoSQL, grafowe to jest przyszłość, być możę “ale nie uprzedzajmy faktów”.
Przez prawie pół wieku systemy informatyczne powstawały w oparciu o bazy relacyjne, i uwaga dalej powstają. Czy to dobrze, czy źle? Nie mi oceniać, fakt jest jednak taki, że na swojej drodze z relacyjnymi bazami danych spotkasz się nie raz.
Zrozumienie koncepcji relacji, zasad A.C.I.D, architektury (jak faktycznie wygląda baza danych) i zapoznanie się z samą bazą od przynajmniej jednego dostawcy to rozsądne minimum.
Bazy nierelacyjne (NoSQL) – główne koncepcje + kilka poglądowo przejrzeć
Not Only SQL, ano właśnie – nie tylko SQL. Nie, zastępstwo dla SQL-a. To ważne, podobnie jak słowo komplementarne, czyli dopełniające / uzupełniające.
Tak postrzegam rolę systemów NoSQL, jako systemy komplementarne dla systemów relacyjnych. Używane tam gdzie potrzeba, z uwzględnieniem ich specyfiki. Czy można “przepisać” system z bazy relacyjnej na bazę nierelacyjną, pewnie można, tylko po co?
Zapoznając się z tematyką baz NoSQL, zwróć uwagę na kluczowe koncepcje i podział baz nierelacyjnych – bazy klucz wartość, bazy dokumentowe etc. Zwróć uwagę, gdzie są wykorzystywane, jak “duzi gracze” ich używają (np. Uber, Spotify).
W materiałach poniżej znajdziesz książkę, gładko wprowadzającą w tą tematykę.
Hurtownie Danych (Kimball) + Zarządzanie Jakością i Metadanymi
Gdzieś te wszystkie dane trzeba trzymać, hurtownie danych czy popularne ostatnimi czasy date lake, szybko nie zniknął a i problemy z jakimi się borykają są ciekawe.
W tym kontekście warto zerknąć na podstawy architektury i zagadnień hurtowni danych od Ralpha Kimballa. W swoich książkach, ale również na stronie ( https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/) znajdziesz sporo informacji i dobrych praktyk w konkteście modelowania, zarządzania i ogólnie pracy z danymi.
Pamiętaj, że technologie się zmieniają, jednak temat metadanych, jakości danych, ról w zespołach związanych z przetwarzaniem danych zawsze będzie aktualny.
Procesy ETL / “Strumieniowanie” danych + eventy (patrz jak robią to inni – Uber / Spotify / Netflix etc.)
Schodzimy do szczegółów czyli samego smaczku przetwarzania danych. I nie mam tutaj jednej wspaniałej recepty na wszystko.
Podejście i sposoby rozwiązywania problemów, będą się różnić w zależności od Twojego miejsca pracy – tak przynajmniej przypuszczam. Z własnego doświadczenia, zawsze są jakieś różnice 😉
Co jednak na pewno warto robić, to warto śledzić jak takie tematy są adresowane przez firmy, które na danych opierają swój biznes w znacznym stopniu. Uber, Spotify, AirBnB, Netflix w internecie znajdziesz blogi tych (i innych) firm czy wpisy konkretnych pracowników. Opisujące często w szczegółach podejście do architektury, czy rozwiązania konkretnych problemów.
Jest to zwykle spora dawka wiedzy, ale też dobry materiał do tego żeby rozważyć jak dane podejście sprawdza sie u innych i czy jest potrzebne u Ciebie?
Big Data (Lambda Architecture)
Popularny temat, każdy ma big date, mało kto wie co z nią zrobić … Możesz rzucić się na jakąś technologie a po miesiącu się okaże, że w sumie jest na rynku już coś innego.
W tym jak i w poprzednich akapitach skupiłbym się na ogólnym podejściu. Poznaniu problemów z jakimi Big Data musi się mierzyć i potencjalnych rozwiązaniach. W miarę zgłębiania tematu, zdasz sobie sprawę, że problemy mogą być logicznie proste, ale w przypadku implementacji nie jest to wcale takie trywialne. Konkretne rozwiązania / problemy mogą stać się Twoją specjalizacją, ale “nie uprzedzajmy faktów”.
DATA ENGINEERING – MATERIAŁY
- Mój Newsletter – https://datacraze.pl | https://zrozumsql.pl
- Książka: Bill Karwin – SQL Antipatterns: Avoiding the Pitfalls of Database Programming
- Książka: Markus Winand – SQL Performance Explained
- Książka: Alex Petrov – Database Internals: A Deep Dive into How Distributed Data Systems Work
- Książka: Ralph Kimball, Joe Caserta – The Data Warehouse ETL Toolkit
- Książka: Ralph Kimball, Margy Ross, Warren Thornthwaite, Joy Mundy, Bob Becker – The Data Warehouse Lifecycle Toolkit
- Książka: Martin Kleppmann – Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- Książka: Luc Perkins, Eric Redmond – Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement
- Książka: Nathan Marz, James Warren – Big Data
- Książka: Mark Needham, Amy E. Hodler – Graph Algorithms: Practical Examples in Apache Spark and Neo4j
- Blog / Twitter: Airbnb Data – https://twitter.com/AirbnbData
- Blog / Twitter: Twitter Eng – https://twitter.com/TwitterEng
- Blog / Twitter: Netflix Engineering – https://twitter.com/NetflixEng
- Blog / Twitter: Uber Engineering – https://twitter.com/UberEng
- Blog / Twitter: Spotify Engineering – https://twitter.com/SpotifyEng
- Blog / Twitter: SQL Daily – https://twitter.com/sqldaily
- Podcast: Maciej Aniserowicz – Devstyle (odcinki o danych / BI etc.) – https://devtalk.pl/
- Podcast: Software Engineering Daily – Data – https://podcasts.apple.com/ca/podcast/data-software-engineering-daily/id1232093653
- Materiały Uczelnia Bazy Danych: http://wazniak.mimuw.edu.pl/index.php?title=Zaawansowane_systemy_baz_danych
- Materiały Uczelnia Hurtownie Danych: http://edu.pjwstk.edu.pl/wyklady/hur/scb/
DATA ENGINEERING – KOGO ŚLEDZIĆ
Lista poniżej mogłaby być kilka razy dłuższa. Postanowiłem się skupić na osobach / firmach / produktach, które najcześciej przewijają się u mnie i od których czerpię najwięcej informacji.
- Twitter: Martin Kleppmann – https://twitter.com/martinkl
- Twitter: Grant Fritchey – https://twitter.com/GFritchey
- Twitter: Simon Whiteley – https://twitter.com/MrSiWhiteley
- Twitter: Planet PostgreSQL (stricte o PostgreSQL) – https://twitter.com/planetpostgres
- Twitter: Markus Winand – https://twitter.com/MarkusWinand
- Twitter: Firmy (jak wyżej AirBnB / Uber / Spotify etc.)
ANALITYKA I WIZUALIZACJA DANYCH
Tutaj sprawa jest o tyle skomplikowana, że można wpaść “w sektę” produktu np. Power BI / Qlik i pięknie sobie radzić w niszy. Ja jednak kolejny raz radziłbym się skupić na rzeczach wspólnych w temacie tj. problemach biznesowych i opcjach ich rozwiązania w różnych technologiach.
Analityka i Wizualizacja Danych – Podstawy
Metryki Biznesowe Finansowe
Tematy związane z: Balance Sheets, Income Statements, Rolling Orders, Sales etc.
Metryki Biznesowe Magazynowanie / Logistyka
Tematy związane z: On Time Delivery, Manufacturing Planning, Freight Costs + Shortest Paths etc.
W powyższych przypadkach, nie znalazłem wspaniałych materiałów żeby ułatwić Ci start, raczej ogólne rzeczy. Pamiętaj jednak, że w swojej podstawowej formie te tematy będą wspólne pomiędzy firmami. Mogą być różnie zaimplementowane / różnie prowadzone i egzekwowane, ale koncepcyjnie cele tych metryk będą takie same.
Szukaj konkretnych tematów na blogach branżowych.
Odpowiednie przedstawienie wyników (design warstwy wizualizacyjnej)
Dobra wizualizacja to sztuka sama w sobie. Nie jest trudnością nawrzucać danych z różnych źródeł i zrobić X zakładek w Excelu i przesłać to do biznesu niech sobie radzi 😉
Dobry design jest też często rzeczą umowną i dla każdego definicja “dobry design” może być różna. Jednak jest kilka podstawowych zasad wizualizacji danych, które warto znać.
Często są one opisywane przez producentów różnych rozwiązań Analitycznych / Business Intelligence – patrz Qlik / Tableau czy Power BI.
Możesz też zerknąć na dokument przygotowany przeze mnie, otrzymasz go po zapisie na Newsletter.
Dostępne narzędzia na rynku
Tutaj pomocne mogą okazać się wszelkiego rodzaju zestawienia np.
- Gartner BI Magic Quadrant Report – https://www.gartner.com/en/webinars/3900973/the-2019-analytics-and-bi-magic-quadrant-highlights
- ToughtWorks Technology Radar – https://www.thoughtworks.com/radar
itp.
Jak działają produkty z rynku wady i zalety (przetwarzanie in-memory, przetwarzanie danych (data lineage) etc.)
Analityka i Wizualizacja Danych – Materiały
- Mój newsletter 😀 (https://datacraze.pl )
- Książka: Stephen Few – Information Dashboard Design
- Książka: Jerry Z. Muller – The Tyranny of Metrics
- Książka: Martin Klubeck – Planning and Designing Effective Metrics
- Książka: Martin Klubeck – Metrics: How to Improve Key Business Results
- Książka: Alberto Cairo – The Functional Art: An Introduction to Information Graphics and Visualization
- Książka: Alberto Cairo – The Truthful Art
- Książka: Alberto Cairo – How Charts Lie
- Power BI: https://predica.pl/blog/powerbi-data-analytics-report-tips/
- Power BI Blog: https://blog.crossjoin.co.uk/
- Power BI Blog: https://datachant.com/?s=power+bi
- Qlik Top 40 Blogs: https://www.askqv.com/blogs/
- Qlik Blog: http://qlikblog.pl/
Analityka i Wizualizacja Danych – Kogo śledzić
- Twitter Qlik: Henric Cronstrom – https://twitter.com/HenricIC
- Twitter Qlik: Rob Wunderlich – https://twitter.com/QVCookbook
- Twitter Qlik: Michael Tarallo – https://twitter.com/mtarallo
- Qlik: Jacek Harazin – http://qlikblog.pl/
- Osoby i instytucje wymienione w Inżynierii Danych
DATA SCIENCE | UCZENIE MASZYNOWE
W obszarze data science / uczenie maszynowe, mam najmniej doświadczenia, dlatego tutaj szukałbym rady wśród innych specjalistów. Zbiór poniżej to moja czysto subiektywna opinia.
Warsztaty o których słyszałem sporo pozytywnych opinii lub sam brałem w nich udział. Osoby udzielające się w środowisku czy popularyzujące wiedzę z tej właśnie dziedziny.
Na pewno można by sporo dodać w tej sekcji, ale zostawiam to już Twojej ciekawości.
DATA SCIENCE | UCZENIE MASZYNOWE – NA CO WARTO ZWRÓCIĆ UWAGĘ
- SQL
- Python
- Notebooks (przykład: Jupyter)
- Data Cleaning
- Klasyfikowanie Danych
- Dobór Cech (Feature Engineering)
- Testy A/B
- Sieci Neuronowe
- Zadawanie dobrych pytań 🙂
DATA SCIENCE | UCZENIE MASZYNOWE – MATERIAŁY
- Kurs Coursera: https://www.coursera.org/learn/machine-learning
- Kurs Coursera: https://www.coursera.org/learn/neural-networks-deep-learning
- Kurs Udemy: Frank Kane – Machine Learning, Data Science and Deep Learning with Python – https://www.udemy.com/course/data-science-and-machine-learning-with-python-hands-on/
- Kurs Udemy: Kirill Eremenko – Python A-Z: Python For Data Science With Real Exercises! – https://www.udemy.com/course/python-coding/
- Kursy DataWorkshop: Praktyczne Uczenie Maszynowe / Praktyczne Prognozy Szeregów Czasowych – https://dataworkshop.eu/
- Podcast: Vladimir Alekseichenko – Biznes Myśli – https://biznesmysli.pl/
- Podcast: Data Skeptic – https://dataskeptic.com/
- Podcast: Master of Data – https://www.sumologic.com/resources/podcast/
DATA SCIENCE | UCZENIE MASZYNOWE – KOGO ŚLEDZIĆ
- Twitter: Vladimir Alekseichenko- https://twitter.com/slon1024
- Twitter: Andrew Ng – https://twitter.com/AndrewYNg
Powyższe punkty nie wyczerpują tematu, to oczywiste, ale na pewno jest to solidna podstawa, do tego żeby zacząć przygodę z danymi.
Jeżeli chcesz dodać coś do tej listy, pisz śmiało w komentarzu.
Dzięki,
Krzysiek
Przydatny zbiór materiałów, zwłaszcza linki do twitterowych profili, których sporej liczby wcześniej nie znałem (nie siedzę aktualnie za bardzo w inżynierii danych, ale mimo to lubię być w miarę na bieżąco z innymi dziedzinami informatyki). Pozdrawiam!
Hej Maciej, dzięki za komentarz, fajnie że materiały dały wartość!
Ciekawy artykuł, ja zaczęłam kształcenie w zakresie analizy danych na WSKZ-cie, jestem na drugim semestrze podyplomówki z tego zakresu. Uczelnię mogę polecić, bo już teraz czuję się dobrze przygotowana do tego, aby szukać pracy jako analityk, a całość nauki odbywa się online.